Making a game with my son
One morning, my son woke up and came downstairs, deep in thought. He looked up at me and said, “Can we make a game, Mummy?” He’s seven and he’s called Jacob.
He told me his game was called Exploding Kitties. He described the mechanics. Bad guys patrol up and down. If they see the player - a kitty - they laser them with their eyes and the kitty explodes. If the kitty can sneak behind a bad guy, it can scratch and kill him.
I had a little game making kit already. A mobile web app. An update and render loop, game objects.
I showed Jacob how to add game objects to the level. He added some red squares for the baddies and a blue square for the kitty.
I can’t tell you how magic it was to see him use something I made.
I said, shall we make the kitty move? He said yes. I prompted Cursor, “Make it so when the player taps the screen the blue square gradually moves to where they tapped.” Cursor generated the code and applied it. The mobile app, served on localhost and made available over WiFi, refreshed on my phone. Jacob tried tapping the screen and the kitty moved to where he’d tapped.
In the past when we’d made games together, the programming had been too slow for Jacob to stay engaged. Now, with code gen, the feedback loop was fast enough to keep his attention.
I told Cursor to add a prompt input box to the game itself. I wired up a little backend route that could receive the prompt and pipe it through for Claude Code to implement.
The UI for modifying the game was now built into the game itself. Jacob and I could both work on the phone. A shared headspace through a shared device.
Jacob said he wanted to draw proper pictures for the kitty and the bad guys. I typed into the phone, “Create a pixel editor on the game object properties screen. Store the pixel art on the game objects.” Two minutes later, Jacob was poring over the throne, drawing the kitty in the pixel editor, enthralled. It reminded me of when my Dad and I would make icons in ResEdit on the Macintosh.
After Jacob had added the kitty I said I had an idea. I typed in, “Get rid of this prompt box and replace it with a button that records audio. Use OpenAI to transcribe the audio. Send the transcription to the Claude Code backend route as before.”
The record button appeared. I asked Jacob what he wanted to change about the game next. He said, “I want to do bigger drawings.” I said, “Go ahead and tell it yourself”. He tapped the record button and said, “Make the drawings bigger,” and I added, “Like 10 by 10, right?” And he said, “Yeah,” and tapped the button to stop the recording. Half a minute later, he had a bigger canvas, and started drawing the bad guys.
Jacob can type, but slowly. Now he could speak instead of typing and build the game himself.
A fast feedback loop. Software with the edit controls built right in. A shared device. An accessible medium of expression. My son and I, in the same headspace, making something together. Magic.
I can teach you to program with AI
tl;dr: I’m offering coaching sessions where I teach professional engineers a smooth, stay-in-flow technique for AI-augmented programming.
All the nitty gritty tips and setup were very helpful.
— Andrew J.
Let the computer make you more productive
My first job after university was working at a software company on their huge Java desktop application. The architecture, complex and winding, made the code very hard to follow. Layer upon layer of indirection meant that trying to follow the flow of execution led to cognitive overload.
Fortunately, the company, though almost unflaggingly tight-fisted (bring your own cake on your birthday), bought IntelliJ for every developer. It had a feature, go to definition, where you could click on a method call and jump to the implementation. This made it possible to understand the byzantine code.
Which brings me to AI.
As programmers, we feel comfortable using tools to make us more productive. Generating code with AI is a natural next step in letting the computer help us.
Three times more productive
With code generation, building features goes much faster. I can be declarative (“add a button…”). I can get an implementation of a stock algorithm (“implement A* with this contract…”) I can zoom in when I need to (“wait, don’t duplicate that state…”).
Programming is a craft. Getting better is the slow process of accreting little techniques and intuition. But there are some core techniques you use all the time. For example, moving in small steps to keep the code compiling.
AI-augmented programming is also a craft. And there are also some core techniques. But they’re different. That one I described above isn’t even really a thing for AI-augmented programming. It’s too low level.
One core technique for AI-augmented programming, maybe the core technique - describe a feature, attach relevant code context, skim the code as it’s generated, let the agent fix lints and type errors, try out your new feature.
This isn’t a cobbled together set of manual steps. It’s an absorbing process where you stay in flow. And it’s a single technique that you’ll use all the time.
When building features, I estimate I’m three times more productive than I was a year ago.
I can teach you
I’m offering ninety minute sessions where I teach this feature-building technique. It’s one-on-one coaching for full-time, professional engineers. At the end of the session, you’ll have built a feature using this technique. And you’ll be set up to keep cranking out features forever.
As a bonus, I’ll teach you the literal one weird trick that makes programming with AI even faster. It’s there in plain sight, but hardly anyone does it. Here’s a hint - talking is faster than typing, but reading is faster than hearing.
Book a session
To book a session, email me at mary@maryrosecook.com.
The first person who signs up for a slot will pay the super-duper introductory price of $0. The second person will pay the merely super introductory price of $100. After that, the price is $300.
To help us get the most out of the time, include in your email -
- Which code editor and terminal you use.
- A project you’re working on and a feature you’d like to add to it in our session.
Talk soon!
Using AI to build a tactical shooter
Enemy AI
My latest side project is a 2D shooter where the enemies plan their attacks. I’m using a technique called Goal Oriented Action Planning. This approach was used in an old game from the 2000s called F.E.A.R. It was a sort of spooky tactical shooter. Think Rainbow Six but with that creepy girl from The Ring hanging about the place. In FEAR, the enemies could flank the player and provide suppressing fire. They could stay in cover and coordinate with each other.
More side projects with AI-augmented programming
Why am I making this? It seemed like it would be fun to try a structurally simple 2D game with tricky enemy AI.
In the age of programming with AI, it’s much easier to follow this kind of whimsy. I’m more productive and I can get to the interesting stuff more quickly.
Productivity hack
You know that film with Bradley Cooper*, where he takes a drug that makes him super focused and productive, but he ends up ruining his life? Well, I’ve found something similar.
Livestreaming.
If you want to trade some of your lifespan and peace of mind for some productivity, just record yourself working. It’s quite stressful. You’re worried about making blunders in front of other people. You can’t take breaks. You definitely can’t start scrolling X.
But you will get a lot done.
Game tape
Everyone’s eternally wanking on about Camp 4†. I wasn’t there, but I think X might have it bested. It’s awash in scenius. The field or tradecraft of AI-augmented programming is proceeding so unbelievably fast. And the best place to learn about it is in ephemera and asides crammed into tiny boxes dispensed by a misfiring slot machine.
So, here is a contribution to the effluvial stream. A video of me working on the 2D shooter. You can see me plan out the project and generate the code that lays out the level, implements player movement, and implements collision detection. Pretty good for an hour and fifteen minutes.
Though extemporaneous, the video outlines a powerful AI-augmented workflow for writing software -
- Plan and iterate on the plan§ with AI, solving many design problems at the spec stage.
- Get the AI to implement the first milestone (often as a one-shot).
- Check off the milestone and move to the next one.
Some of the techniques I demonstrate -
- Using voice-to-text to prompt the LLM. Much faster than typing.
- Staying in flow by using voice and Cursor Agent mode. One UI that lets me plan, refine and generate code. No stitching together tools or copy/pasting.
- Using the AI as a rubber duck to think through problems.
- Also using the AI as a thought partner to come up with better solutions.
- Asking the AI technical questions (e.g. on ECS architecture idioms).
- Keeping the spec short and dense for easy manipulation and scanning.
- Avoiding unnecessary abstraction, but also defining a robust architecture to keep the project extensible.
- Using popular technical approaches (ECS, SAT collisions) to ensure a robust approach and also make it easier for the AI to one-shot correct implementations.
* Limitless is not a very good film. But if you like Bradley and like good films, definitely watch The Place Beyond the Pines. My Dad and I saw it a continent apart - him in England and me living in New York - and we still talk about it.
† Rock climbing scenius at Camp 4.
§ Thanks to Geoffrey for teaching me this!
Explore, expand, exploit
A few months ago, I started sleeping badly.
I had been excited about AI since ChatGPT came out. I’d loved using Cursor to help me program since Jay had told me about it over the phone as I walked from Eureka Heights back home to Noe Valley.
But, in January, something changed. The proximate cause was a flood of new AI releases. o3-mini, Deep Research, Lightpage. Every week, more intelligence dropping from heaven into my lap.
But the bigger change was that I was getting more productive, faster.
Type in a few sentences, get a hundred lines of code. A feeling of vertigo.
More than that, I could learn a new technique in an hour and become significantly more productive.
This was in stark contrast to the previous twenty years I’d spent learning to program. That was a slow, accretive grind. A new technique for encapsulation. A more refined understanding of what it means to “repeat yourself”. Learning that you could step-debug a production web app.
My friend, Sam, has this model of learning as building a graph. Each node is a piece of information or a skill or a behavior. They’re interconnected. Acquiring a new node of knowledge isn’t too hard. It’s a bit harder to elaborate it. Which is to say, to connect it to the existing nodes in your graph.
But the real fucker is when you have to unmake a part of your graph. You get cognitive dissonance because some of the nodes contradict each other or need to be pried apart or replaced. It’s very painful to disassemble the graph and remake it. Learning to program was a lot of that.
Learning to build software with AI feels completely different. It’s much closer to learning a new discipline. Certainly, the old way of programming is relevant. But all the power comes from the new techniques in this new field that doesn’t even really have a name.
Further, a lot of the new techniques involve a new workflow. Copy code from your editor into GPT, make a request, get code back, paste it into your editor. No, don’t do that any more. Instead, start by selecting code and then pressing ⌘-L. No, wait, stop. Just press ⌘-L, make a request, get code, press the Apply button. No. New move. Press ⌘-I, make a request, scan the code as it’s added to the repo, run and check the behavior. No, wait, this is the killer. Iterate on a PRD first, then tell the LLM to write the code in one shot.
Adopting a new workflow induces cognitive strain because it requires extra supervision. And it requires willpower to not just do things the old safe way. It’s exhausting.
So the destabilization is three things. First, the pure sensation of doing something with a new, startling ease. Second, the knowledge that I can put in ten minutes or an hour or two and get significantly faster at building software. Third, my methods and working life are changing every day.
With gains like that to be had, why wouldn’t I do it all the time? Stay up later. Get up earlier. Watch AI programming game tape with lunch. Spend an hour learning rather than working, then make up the loss in the same day.
There’s also a problem. There is so much information. Every day is a deluge of new tools, techniques and streams. Which ones are worthwhile? I have a long list of stuff I’ve been meaning to try, that seems promising, that worked and I feel I should be doing more. Sometimes I’ll watch a forty-five minute YouTube video of someone vibe coding and it’ll be useless. Other times, I’ll skip forward and hit a nugget so juicy that I’ll become terrified I’m missing these sorts of things all over the place. Sometimes a technique will seem unpromising but, several hours in, will click.
For this, at least, I’ve found something of a solution. When you’re in a fast-changing environment with high uncertainty, what do you do? Well, Civilization, the video game, is a good guide. You explore, expand, exploit.
You spend a good deal of time exploring widely. Things are changing rapidly and there’s a lot to learn. Many explorations will be fruitless and that’s totally fine.
When you find something good, you expand your technique to incorporate it. Did you hear about an obviously useful tool? Install it! Have you been refactoring your code to make it easier to change? Do it!
And when something’s working, you exploit it as much as possible. It’s easy to learn a cool new technique then forget to use it. Don’t. Instead, bring it back.
I keep a list with these three categories. Explore, expand, exploit. And I spend some time on each.
It’s something to cling to.
Game design conversation
Below is a conversation about game design. I posted it on X and it got basically no likes. Which is insane because it’s magical.
It comes from a documentary about Housemarque, an indie game studio, making their game, Nex Machina. The game director and head of marketing at Housemarque are discussing feedback they’ve received from Sony, their financial backers.
Harry Krueger, game director, quoting Sony — “Overall, I have to say I’m disappointed by this milestone. I would have expected the gameplay to be much more balanced and layered at this stage. The smaller details still remain unclear. And the gameplay is lacking the depth present in things like Resogun and Alienation, and which I know the team is capable of. The other impact I’m concerned about here is that we’re still looking to reach the quality needed to make this a big announcement in one of our upcoming events.”
Haveri, head of marketing — I hate to call it bullshit, but it is bullshit. When you play a game that’s clearly in the stage that the game is in right now, it’s like, pointing out those obvious flaws. They don’t know how we do shit. We make shit games until they become good games.
Krueger — I actually agree with everything the guy says. It’s good to get an outsider’s perspective, and Sony does give us that fresh perspective in this context. And no one is more disappointed in the lack of our progress than I am.
I’m not worried about any of these individual things. If you ask me about art, yeah, we’re gonna get the art. If you ask me about gameplay? That too. The editor? Roger. The question is, can we do all of the above in the next six months? That’s where I start getting seriously nervous and start freaking out.
Haveri — Drink.
Krueger — Well, fuck it, yeah. I’ll have a sip.
Haveri — The company is not going to collapse.
Kreuger — I’m gonna collapse before Housemarque does.
You know, Eugene [Jarvis, creator of Robotron and Defender] actually had some pretty valuable insight, unsurprisingly. He was talking about Robotron yesterday. And I was just kinda trying to tap into what the creative process was for that game. Because it has been my suspicion that it was an accident to a large extent, you know. It’s a bit rough around the edges, and I think that’s part of its charm.
And Eugene also basically said this thing that I’ve never considered before, you know. That basically you just, you try some shit out, and if you reach a point where it actually works, then don’t touch it. Just fucking leave it and move on.
I can’t do that. As a person, I’m obsessive, and with Resogun, it was, like, two years fine-tuning the controls. And not a single review comments on the controls. You know why? Because they’re invisible. And you know why they are invisible? Because I worked my ass off to make them invisible.
Maybe I’m more of a creative or artistic person than I am a managerial or a leadership type. I don’t know. But doing both at the same time is killing me.
Haveri — Maybe you shouldn’t be the lead then.
Kreuger — Maybe I shouldn’t be.
Haveri — Do you have any other worries in your life?
Kreuger — I probably haven’t mentioned this, actually, but it looks like I’m going to become a father soon.
Haveri — All right. Hug it out.
Look at all these moments -
They get negative feedback which is difficult to cope with. The reaction is both to reject it, which is partly right, and to embrace it, which is also partly right.
The game director gets overwhelmed by the amount of work that needs to be done. And the marketing person gives him a pep talk.
The director talks about the creative approach of trying a bunch of stuff until you find something that works. But that you can mess it up by trying to refine it too much.
The director talks about how he’s not really that guy. That he refined the controls of their previous game for two years, and that’s why they’re so good. And that this approach is in tension with the try a bunch of stuff approach.
And, then, amidst all this stuff about work and art, the game director says he’s going to become a dad.
Become an AI-augmented engineer
My goal is to persuade you that, if you write code, you should use AI to help you. Here’s why.
You want to be productive, and AI makes you more productive
Your life as an engineer has two parts. First, you build software. You want to ship features. Earn money. Second, you work at getting faster at building software. You want to ship more features. Earn more money. So, you’ve dedicated at least part of your career to getting faster. You’ve switched to TypeScript. You’ve learned to plan an architecture. You’ve set up IntelliSense. You’ve learned some educational psychology. You’ve read books on software design. You’ve invested time in getting faster. You’d certainly take advantage of a new way of getting faster. Especially one that outstrips all the others. I’ve helped build well-known products. I’ve taught programming. I’ve been a professional programmer for twenty years. A year ago, I started using AI to help me program. My productivity has increased more in the last year than it has in the previous nineteen.
Programming with AI feels good
Building software with AI feels better than building without. Let me tell you about it.
Sculpting with a collaborator
I was adding a new sub-system to an app. This sub-system needed to wrap another system without creating a nest of couplings. I sketched out a few approaches, but each had problems. So I asked Cursor’s chatbot how it would structure things. It gave me a nicely de-coupled solution. I asked it to refine the solution to enforce an invariant. It updated the solution. I implemented the full version and it worked great. This felt different. First, I wasn’t alone with the problem. I had a partner helping me. Second, I could externalize my thoughts which helped me think them through. Third, if programming can be driving into a wall again and again, this felt more like skiing down a mountain, turning and gliding.
Striding into the unknown
I recently built my first VSCode extension. Extensions can alter many different parts of the VSCode UI. Each thing I implemented required a different function or module. I certainly could have found out which one to use by trawling through the docs or googling around. But, with AI, I could just ask, “How do you add an annotation to a line of code?” It felt like putting out my hand and having the correct tool placed in it. Other times, I needed to find an idiomatic approach. For example, I asked if I could render markdown in a VSCode sidebar. GPT warned me that this would be difficult and said I could use a WebView, instead. I felt confident in unfamiliar territory. I felt that I wasn’t going to waste a ton of time on the wrong approach.
Conjuring from nothing
I was working on a little arcade game. When the player died, I wanted to render a shower of particles. I knew how to write that code. Writing it would just take time, and would be boring. So I typed into GPT that I wanted a particle system that used a normal update/render lifecycle and I pasted in the code from another source file as an example of that lifecycle. GPT whirred away and gave me some code. I created a new file in my repo, pasted in the code, and it worked first time. In about five minutes, I’d gone from an idea to forty lines of code and a new feature in my game.
Not stepping, bounding
Overall, the feeling is like those videos of Neil Armstrong on the moon. He’s bounding. Programming in the normal way feels like walking. You type out each expression, stepping incrementally toward your goal. When programming with AI, each move is bigger than a step. You lift off the ground. It requires more forethought, but, because you make more progress with each move, it feels like flying.
The interface of an interface
It has been said that a novel user interface idea is not a durable differentiator for a product. The cycle is like this. An idea is conceived and integrated into a product. It provides value to the users of the product, and, initially, brings market differentiation and success to the product. But then it’s copied into other products and the market differentiation is lost.
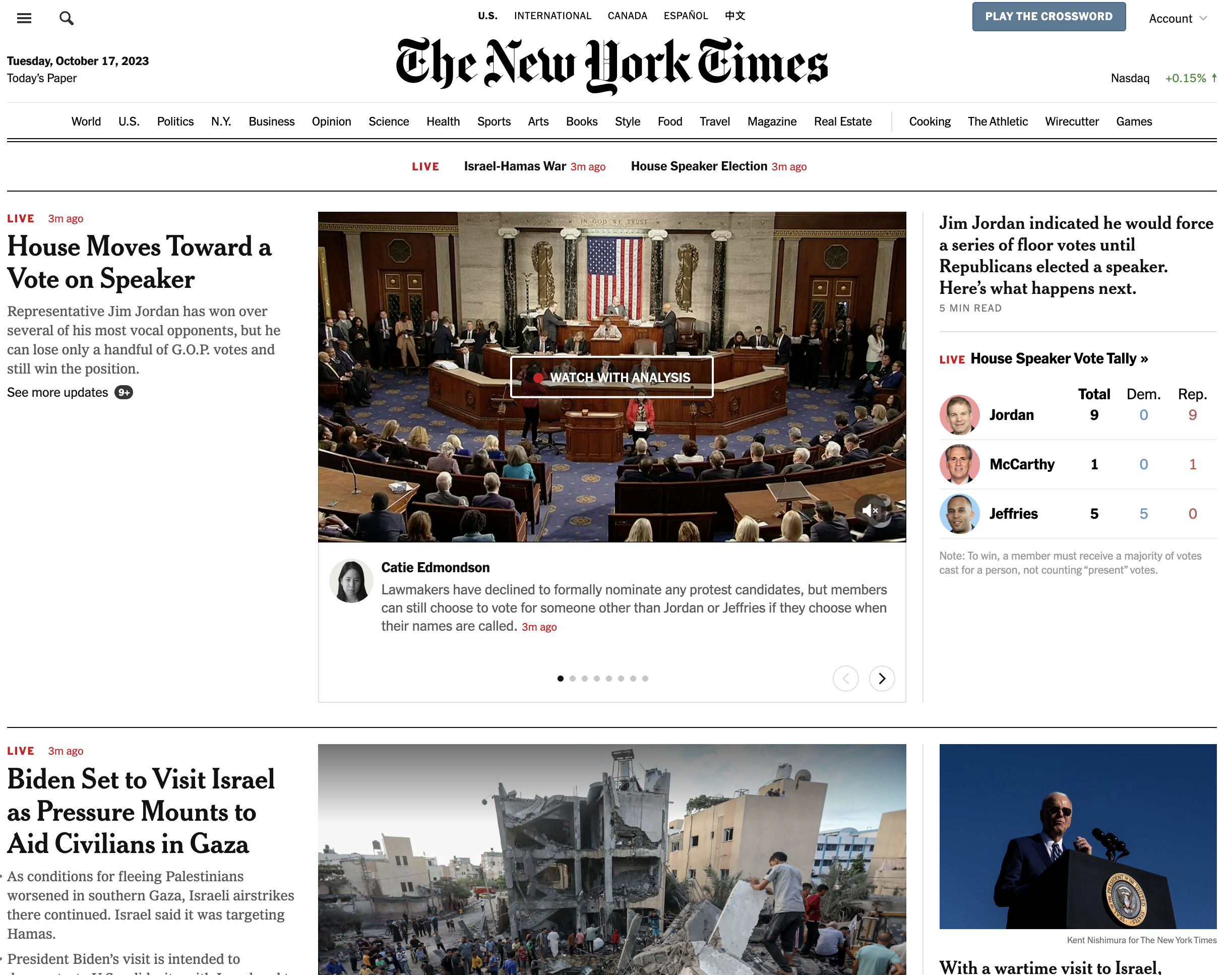
However, an innovation is not universally adaptable. For example, the New York Times could not integrate pull to refresh into the traditional layout of their front page.
Pull to refresh is a set of interlocking interfaces -
- A single column
- …on a touch screen
- …of pieces of content
- …with the same structure
- …arranged in chronological order
- …that can be scrolled vertically
The front page is extremely well suited to these sub-interfaces. Its interface can integrate with four of the six pull to refresh sub-interfaces - 2, 3, 4 and 6. But it’s not structured as a single column (1) and it’s not arranged in order of newness (5). These mismatches are enough to make it difficult to integrate pull to refresh.
But not impossible. Thinking of the traditional New York Times front page as a single interface isn’t quite right. Just like pull to refresh, it’s really a set of interlocking interfaces -
- Pieces of content that are headlines and blurbs.
- Lists of pieces of content
- Images
- Navigation
The most important interface, the headline and blurb, is compatible with pull to refresh. Take a bunch of them, put them in scrollable column, and, boom, they’re ready to integrate with pull to refresh.
So an old interface can be reconfigured to integrate with a new interface. A few observations.
First, integrating interfaces can be more or less harmonious.
In the case of pull to refresh and the New York Times front page, the integration was reasonably harmonious. A grid-like front page became a list. The pull-to-refresh spinner lives at the top. The fact that the list of content items that gets refreshed is separated from the spinner by the unrelated masthead, date and ticker only brings a small amount of discordance.
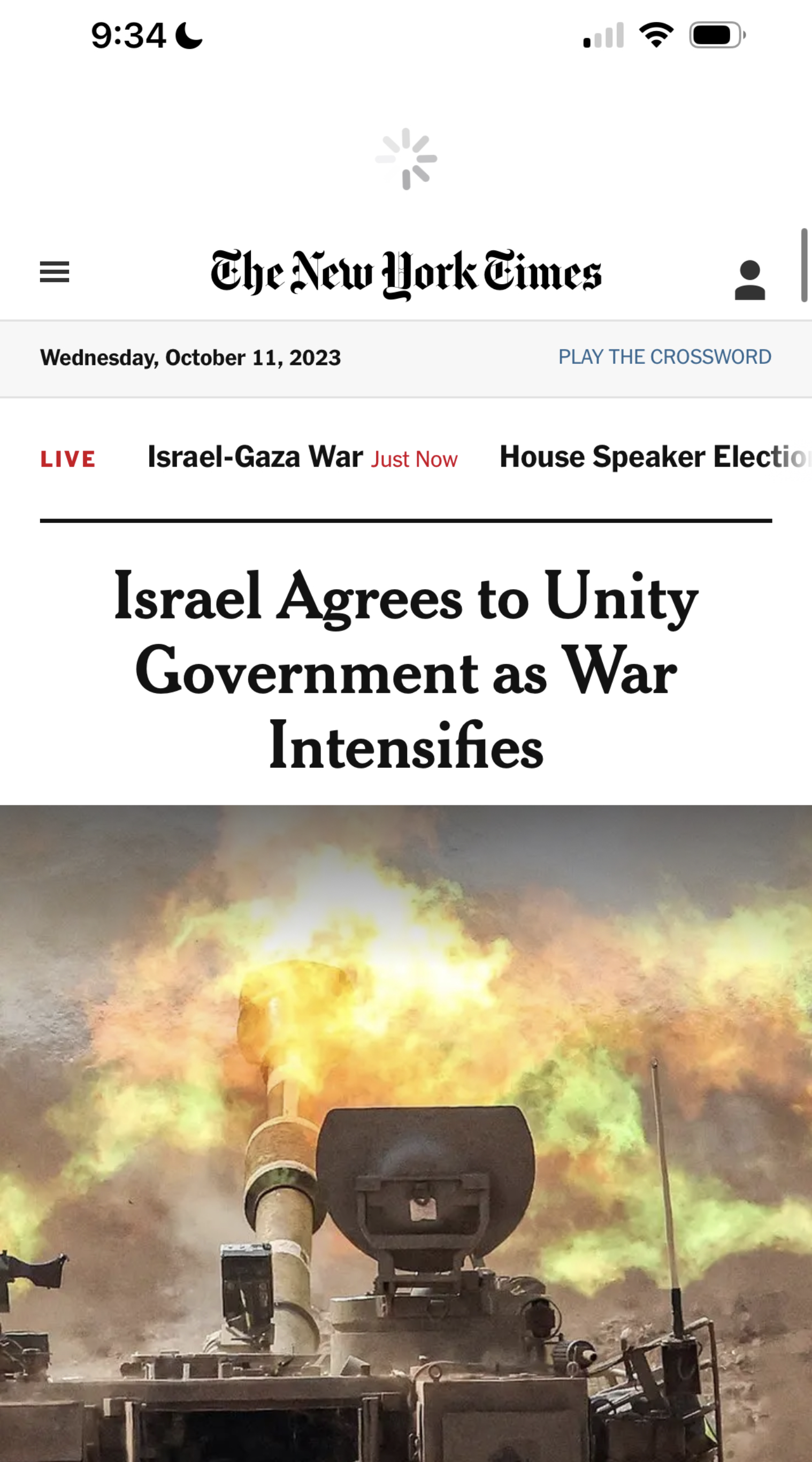
The integration of disappearing photos into Instagram was less harmonious. Stories live in a separate part of the product to the old posts interface and bring a new set of interface conventions for interacting with them. The differences between the post interface and stories interface were so great that they had to be made separate.

Second, in integrating a new interface, some of the advantages of the old interface are lost. The grid-like front page of the New York Times made important things prominent whilst still showing less important things. The pull-to-refresh version is able to show one most important thing. But the hierarchy of importance has been lost.
Third, in integrating a new interface, some of the advantages of the new interface are also lost. In the pull-to-refresh version of the New York Times, unless the newest piece of content is also the new top headline, the newest content is hidden below the top headline.
Fourth, every product is trapped in the past. Each part of a product’s interface was designed for the world of that moment. But the world changes. So the product is designed for a world that, to some extent, no longer exists. The product can be changed to meet the conditions of the new world, but this is a painful process.
Further, it’s even difficult to stay up to date by copying innovations. Those innovations are adapted for conditions that the product is not adapted for. Pull to refresh is adapted to a world of large volumes of regularly updated content. That’s not the world of the New York Times.
So, seeing an interface as a set of sub-interfaces, each of which needs to integrate with other interfaces, has helped me understand why it’s not easy to successfully copy a UI innovation. And why products get stuck in the world in which they were born.
Is this a good book for me, now?
I used to believe that every book has an objective value. And I used to believe that this value is fixed and universal.
Now, I believe it’s much more useful to say something in this form: this book has this value to this person in this context.
For example, Mindset by Carol Dweck was life changing to me when I read it in 2016.
The “me” part is important because I grew up thinking that intelligence is fixed and my skill in each activity I tried was based on talent and was fixed. So I thought I should to do the things I had a knack for, and I thought that the things I found difficult would stay difficult. Learning about a growth mindset was extremely valuable to me.
The 2016 part - the context - was also important. I’d just spent the last three years working at the Recurse Center, a place and community suffused with the idea that people can grow. I was primed for these ideas.
A second example. Around ten years ago I read You and your research by Richard Hamming. This is an essay by a mathematician who did ground-breaking research into telecommunications. He relates this anecdote:
I had been eating for some years with the Physics table at the Bell Telephone Laboratories restaurant…Fame, promotion and hiring by other companies ruined the average quality of the people so I shifted to the Chemistry table in another corner of the restaurant. I began by asking what the important problems were in chemistry, then later what important problems they were working on, and finally one day said, “If what you are working on is not important and not likely to lead to important things, then why are you working on it?” After that, I was not welcome and had to shift to eating with the Engineers.
I read that ten years ago without effect. I read it again a couple of years ago and it led me to the work I’ve been doing for the last three years. The same text and the same reader. A completely different outcome.
I think what changed is my context. Ten years ago, if I’d even tried to work on foundational problems in my field - programming - I’d just have kind of paddled around and had no idea how to make progress. I didn’t have the knowledge of the history of computing or programming to be able to make any kind of headway. In 2021, I did, because I’d accrued it.
The idea that a book’s value is best judged alongside the notional reader and their current context has some corollaries:
First, reading the books that your heroes cite as important will not necessarily be rewarding. If you admire Bret Victor for his work on computing interfaces, only some of his library will be high value to you because his library also includes lots of books that have nothing to do with UI.
Second, yes, it’s likely that “great books” may be high value in some more universal sense that is independent of reader and context. And, yes, this high value may come from something inherent in the quality of the books, rather than from the fact that they are about themes that are more relevant to more people. Yes, I probably wouldn’t dispute this. But I suspect that relevance to person and context is a better guide to what to read.
Third, book recommendation systems based on your reading history can be helpful, but only so much. You, now, are not represented by your reading history. You’ve changed. Making recommendations based on books you read twenty years ago might produce good books for you, now. But probably not.
What aspects of me and my context affect the value of a book?
First, what are my fantasies? Some of my friends have sci-fi fantasies. They love the idea of living on a space ship and landing on planets and fighting aliens and using advanced technology and all that bilge. That fantasy life appeals to them. Whereas I love the world of P.G. Wodehouse. The gentleman’s life, the flitting from manor to manor, the purloining of cow creamers to avoid the homicidal fellow guest. I don’t think either world is any more rich or meaningful or worthwhile than the other. It’s just personal taste.
Second, what is new to me? A while ago, I started reading The Little Kingdom. It’s a book about the early history of Apple. But I put it aside quickly. It wasn’t a bad book. I just already knew everything in it because I’ve read many other histories of Apple. This same thing can happen when coming much later to a book that was ahead of its time. It can seem like old hat because it’s already part of your cultural context.
Third, what am I ready for? I’m trying to get better at graphic design. I recently read a book about grid systems. It was pretty good. But I’m not really ready for that level of depth, so the book wasn’t very high value to me. This type of context is perhaps the most powerful. It was what was missing with Hamming and present with Dweck. I think it’s the main difference between learning slowly and learning quickly. Vygotsky called it the Zone of Proximal Development. One of my programming students at Makers, Jasper, a skateboarder, called it the Goldilocks Zone.
Fourth, what am I doing right now? I have a book on my shelves called Game Feel that is about making video games that feel physically good to play. I’m really excited to read it. But I’m holding off because I’m not currently making a game where the focus is on a good feel. If I read it at the moment, I’d retain and adopt a lot less of it than if I were to wait for when I can apply it.
These things helps me make better choices. There is another set of techniques that help me make a book as good as it can be for me, now:
First, skipping sections that aren’t good. This is tricky. Reading is a place. The more you skip, the more it becomes browsing. And browsing is not a place. You want to be in the place.
Second, dropping books that aren’t good. I find this hard because I feel good about finishing lots of books. But dropping bad books means I will be able to read so many more good books in my lifetime. When I drop a book, I try to say, “it’s not me. It’s not the book. It’s just not the book for me, now.” Even this is hard. Not getting very much out of Anna Karenina, supposedly one of the aesthetic and emotional heights of human expression and experience, doesn’t feel great. But, that’s the way it goes.
Talk to GPT
I made an Apple Shortcut for ChatGPT. I use it on my:
- Apple Watch - “Hey Siri, talk to GPT”.
- Mac - run the shortcut and type into a text box.
- iPhone - talk or type.
You can use this shortcut too!
- Get an OpenAI API key.
- Install the shortcut by visiting this link on your Mac or iPhone.
- Enter your API key.
Privacy
The API key will remain on your device. Besides talking directly to the OpenAI API, the shortcut runs entirely on your device.
Customize the prompt
You can change the prompt by editing the shortcut in the Shortcuts app on your Mac or iPhone. I find this makes it much more powerful than off-the-shelf wrapper apps like Quora’s Poe.
GPT-4
If OpenAI have granted you access to GPT-4 and you would rather use that than ChatGPT, just change model to gpt-4 in the shortcut.
Things I've made and done
Programming environments
- Code Lauren - An online IDE for beginners. Includes a vm that lets the user run their program forwards or backwards. Watch a demo or try it out.
- Isla - A livecoding interface and programming language for young children.
Games
- Pistol Slut - A platform shooter. Guns, grenades, parallax scrolling, particle effects. The enemies work in teams. I talked about the game at JSConf.
- Empty Black - A puzzle platform shooter. Throw crates, set off bombs, fire missiles, stab with your sword. Featured in Kill Screen, PC Gamer and others.
Frameworks
- Coquette - A micro framework for JavaScript games.
Building to learn
- Gitlet - Git implemented in 1000 lines of JavaScript. I used what I learned building it to write an essay and talk on the innards of Git.
- Little Lisp - A Lisp interpreter in JavaScript and an essay about how it works.
Music
- 10997 - My latest record on Apple Music and Spotify. Recorded on my phone in my kitchen in Berlin.
Essays
- Git from the inside out
- A practical introduction to functional programming
- A Lisp interpreter in JavaScript
- The Fibonacci heap ruins my life
- Walking
Talks
- Mary livecodes Space Invaders
- An intuitive introduction to algorithmic efficiency
- Mary livecodes a drum machine
- Git from the inside out
- Isla: a programming language for children
- Pistol Slut, collision detection, AI, falling in love
Interviews
- Future of Coding podcast
- The Setup - interview about the tools I use