Step
Use Step to get a more precise understanding of how code executes.
You see a code listing. You click on the part of the code that you think will execute next. Then you click on the part of the code that you think will execute after that. And so on.
This is just a proof of concept. You can’t enter your own code, but I plan to change that.

Paper programs animation program
Inspired by Dynamicland, I added a feature to Paper Programs to make each page publish a picture of itself. I used this feature to write a very crude animation program.
The dynamic medium community in London
I want to help foster the community of people in London who are interested in the dynamic medium / tools for thought / interactive simulations for creation or understanding.
Here is a hopelessly narrow set of example projects:
A possible first step. I’ll arrange a meetup. At the meetup, I’ll give a brief talk that provides an overview of some of the interesting projects that I know of. Around the room, there will be posters that give more information about each project. These posters could attract groups of people who might discuss the project, or even get out a laptop and work together on trying it out.
This is just a set of initial bad ideas. If you have thoughts about how I could make them better, I’d love you to email me at mary@maryrosecook.com or send me a reply on Twitter. Thanks!
Why I coach
Makers Academy is a programming bootcamp. I’ve coached there for the last nine months. I love it.
In this essay, I’ll describe some of my favourite parts of coaching. For each part, I’ll explain how my work supports a learning goal at Makers. And I’ll explain how the environment at Makers supports this learning goal.
Note: we refer to our students as developers.
Giving as little help as possible
At Makers, developers lead their own learning. This lets them follow their curiosity. It lets them learn in their own style. It lets them learn at their own pace.
I support the developers with their self-led learning. Sometimes, a developer may ask me for help. Every problem is a chance for them to learn. I want to avoid robbing them of that chance. I want them to wring the maximum amount of learning from the problem. I try to identify the tiniest nudge that will get them going again. Sometimes, we’ll have a Socratic dialogue. Sometimes, I’ll suggest they diagram their current understanding of their problem to uncover wrong connections.
The environment supports self-led learning. Developers work on challenges that are designed to be rich playgrounds for exploring programming topics and practising programming skills. Developers work on team projects where they choose the what they make and how they organise their work.
Debugging learning processes
In some educational environments, the focus is on accumulating knowledge. The measure of success in these environments is: how much does the learner know about a topic? At Makers, we focus on improving processes. These are the approaches and techniques that a developer uses when learning or programming. Our measure of success is: how much have a learner’s processes improved? This means that a developer arrives at Makers as one person and leaves Makers as a different person.
I help developers improve their processes. For example, I run weekly surgeries. Developers discuss programming struggles they’ve had. A developer often describes their struggle as a problem with a programming concept. Through discussion, we try and uncover the skills and behaviours that are the actual cause of the struggle. A description of a struggle might be: “I find it hard to get RSpec syntax right”. Through discussion, it emerges that the developer is trying to memorise syntax, piece by piece. I might suggest they build their skill in mentally parsing syntax. Or, a description of a struggle might be: “I don’t understand database relations”. Through discussion, it emerges that the developer has spent a lot of time reading. We talk about how it is essential to learn by doing. We talk about how they could build a behaviour where they try stuff out in a REPL.
The environment helps developers improve their processes. Pair programming, group work and retrospectives help them reflect on how their processes could be improved. Skills workshops suggest new processes to try. And working on projects gives developers a chance to practice new processes.
Being a role model
At Makers, we help developers aspire to become better programmers.
I support this in a number of ways. Two examples. A developer asked me what programming language would help him explore functional programming further. I took great pleasure in suggesting Clojure. It’s wonderful to be able to share the things I’m excited about. If a developer asks me for help with a programming problem, I might show them a cool technique. Or, I might talk through the source of my intuition about where to look for the problem. It feels good to share techniques from one craft practitioner to another. Sometimes, a developer will ask how I started making games, or how I got a job at Ableton, or how I made a programming language. It feels great to be able to give them advice.
The environment supports the aspiration to become a better programmer. We recommend books and talks by expert programmers. When pair programming, developers frequently work with people who are better than them. This gives them someone to learn from and a standard to aspire to. By encouraging varied projects (from a virtual reality city-builder to an arithmetic interpreter written in Haskell), the environment becomes a community of developers who inspire each other.
Getting better at learning
At Makers, I spend my whole day steeped in our environment. I get to learn about educational psychology. I get to think about learning all the time. I get to reflect on my processes and improve them.
Every time I help someone learn, I improve my own ability to learn.
Summary
In this essay, I’ve talked about some of our goals at Makers. I’ve talked about how I support these goals. And I’ve talked about how the environment supports these goals.
And here’s my greatest joy. As a coach, I’m a part of the environment. But I also get to design the environment.
Want to help? We’re looking for a new coach.
Film listings
I used to love Google Movies. It was a site that listed the films showing nearby. For some films, there was a handy link to the film’s IMDB page, or its trailer. Unfortunately, it was taken down a few months ago. So I built my own.
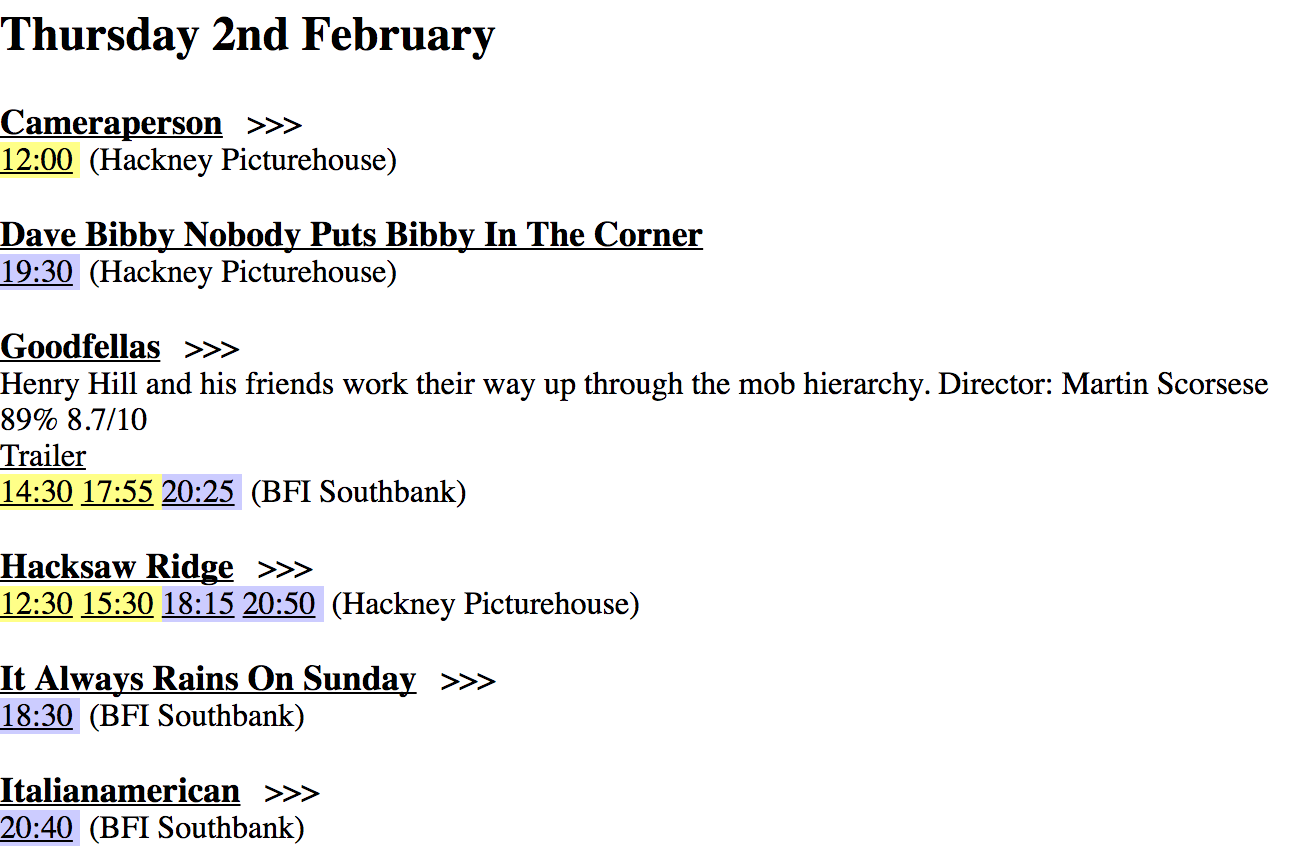
It lets me find out more about a film I haven’t heard of. It lets me quickly scan to find something to see in the next few days. And it lets me find out about that one random screening of Taxi Driver happening at 9.40pm on a Tuesday in three weeks’ time.
Instant GIF search
I spent a couple of days making a prototype of a GIF search engine. My goal was to make it as fast as possible.
Each time the user types a character, the app sends an Ajax request to the Giphy API. When the response comes back, the app extracts URLs for the GIFs listed in the search results. To preload these GIFs, the app sends Ajax requests for each one. When the first image response arrives, the app inserts the corresponding image into the top search result position on the page. When the second image response arrives, the app inserts the corresponding image into the second search result position on the page. And so on. The GIFs are less jarring to the eye because they load from the top of the page down.
Each time the user types a new character, the previous search request and previous image requests are aborted. This saves bandwidth. The app is fast because of this bandwidth saving, React’s fast rendering, and Giphy’s responsive servers.
Sadly, I can’t deploy the app publicly. It doesn’t have any features beyond the ones offered by Giphy, which means it violates their terms of service.
I used Create React App to build my project. This was a dream. No messing around with Webpack. Built-in deployment build script. ES2015 support.
Roper game prototype
For a few days last week, I went to the reading room at the Wellcome Trust and worked on a game prototype.
(Cinematography and set design by Lauren Karchmer, my wife.)
Sam, my friend and colleague at Makers Academy told me about the reading room. It’s great. There are lots of interesting books there, comfy seats and a palatial staircase covered in throw pillows.
I had a few goals with the prototype. First, to try out a Bionic Commando slash Spiderman roping mechanic that I’d had in my head. I wanted to use Box2D for the rope physics. I wanted the player to not be constrained to special roping points or angles. Second, I wanted to keep to a discipline of prototyping an idea and then setting it aside, rather than letting it potter along as a project that eventually ran out of steam.
I made some interesting discoveries.
First, the unconstrained roping angles led me to making the game rely on using a gamepad. This made the game incredibly fun to make.
Second, it was very satisfying to tune the controls so jumping and roping felt good.
Third, if the right stick is used for an essential function, the face buttons (X, O etc) cannot be.
I started by using the left stick for left/right movement and the right stick for aiming the rope. Using X for jump would have meant that the player had to stop aiming to jump, which would have made the character much less agile. I tried jump on one of the trigger (L/R) buttons. This was OK, but didn’t feel as good as X. In the end, I discovered that I could use the left stick for both lateral movement and aiming the rope. So, jump went back onto X and things felt good.
Fourth, though I successfully prototyped the roping mechanic, I have no idea if there’s a game in it. I worked until the core idea was fun, but I didn’t find a way to develop it. Maybe a few more hours tinkering would have revealed a world of developments, or maybe each successive hour would have produced a linear amount more fun, or maybe each hour would have turned up a new dead end. I’m not sure, and I’m not sure how to know.
What I do when a student asks for help
For the last three months, I’ve been working at Makers Academy as a programming coach.
I spend part of my time working with students who have asked me for help. My goal is for the student to learn to learn. To improve my ability to help with this, I wrote down a process that I follow. The process has changed as I’ve learnt more. Here’s the latest version:
Process
- Map the student’s request for help to one of the underlying problems:
- No clear problem explanation
- Want a concrete piece of information
- Not clear on how to implement a piece of functionality
- Not clear about how to implement a piece of functionality, and neither am I
- Want my opinion of their idea
- Want an intro to a topic
- A bug they should be able to solve on their own
- A bug they don’t have the background knowledge to fix on their own
- A bug for which I can’t predict the likely cause
- A bug that will take them a long time to fix
- Apply one of the suggested solutions:
- Ask the student for feedback on my help.
Problems underlying a request for help
The student doesn’t have a clear problem explanation
-
Maybe suggest they follow the escalation process.
-
Help the student clarify their explanation of their problem.
The student wants a concrete piece of information
-
Maybe suggest they follow the escalation process.
-
Maybe suggest they Google their question.
The student doesn’t know how to implement a piece of functionality
-
Maybe suggest they follow the escalation process.
-
Maybe identify and train a developer skill that will help them implement the functionality.
-
Maybe suggest reading material on a topic that will solve their problem.
The student doesn’t know how to implement a piece of functionality, and neither do I
-
Maybe suggest they follow the escalation process.
The student wants my opinion on their idea
-
Maybe suggest they follow the escalation process.
-
Maybe identify and train a developer skill like fast prototyping or diagramming.
-
Maybe identify and train a developer behaviour like reflection.
The student wants an intro to a topic
-
Maybe suggest they follow the escalation process.
-
Maybe suggest reading material.
The student has a bug they should be able to solve on their own
- Maybe suggest they follow the debugging process.
The student has a bug they don’t have the background knowledge to fix on their own
-
Maybe suggest they follow the escalation process.
-
Suggest reading material that will provide the background knowledge.
The student has a bug for which I can’t predict the likely cause
- Run through a partly closed debugging process with the student.
The student has a bug that will take them a long time to fix
- Solve the student’s problem. Make the process as open as possible.
Solutions
Suggest the escalation process
- Make the student feel held first. Then suggest the escalation process. (This link isn’t publicly accessible, I’m afraid. It points to an internal Makers Academy document. The document describes a process that helps the student help themselves. It suggests: gathering words to describe the problem, Googling, talking to a pair programming partner, and asking on the student Slack channel.)
Help the student clarify their explanation of their problem
-
Maybe ask them questions to clarify their request for help.
-
Maybe use 5 whys.
Suggest they Google it
- Make the student feel held first. Then suggest they Google their problem.
Suggest the debugging process
-
Tighten the loop. This means following the flow of execution to find the line of code that’s causing the bug.
-
Get visibility (aka
peverywhere). This means using stdout or a debugger to see the current state of the program.
Suggest reading material
- Suggest a blog post. Or suggest a pill [an internal document that gives a condensed introduction to a topic].
Identify and train a developer skill
For example: diagramming, delegating behaviour, breaking classes into single responsibilities, debugging asynchronous code, 5 whys, falsifying assumptions, following the flow.
-
I can identify a skill that’s lacking by looking at how the student makes their request, how they’ve tried to find the problem and what solutions they’ve tried.
-
To set the student’s expectations, name the skill I’m going to help them train. Suggest they employ the skill to solve the problem. Name the skill at the end of the session to help them remember to use it.
-
Figure out how open the process should be. Maybe the first time that I suggest diagramming, I’ll need to walk the student through it. But, in the future, I should be able to give less detailed support.
Identify and train a developer behaviour
- For example, one of the XP values.
Solve their problem
- If the student has a really tricky problem that will delay them for a long time, it’s often better to just solve it for them so they can get going again. Whilst keeping the process efficient, try and make it as open as possible. Try and explain how I know to try the things I’m trying.
Definitions
Feeling held
- Reassure the student that I’ve heard and understood their request. Reassure the student that I care about them and their request. This may involve explaining why I’m not giving them the answer.
Open process (vs closed)
- An open process is one that helps the student to learn more than a closed process. For example, letting the student type, rather than typing myself, or saying “can you use the filter function for that?” rather than “type dot f i l t e r …”.
Mary livecodes a drum machine
I livecoded a drum machine that runs in the browser. Go to the website to play with the demo, watch the video and read the 114 lines of heavily annotated source code.