Git from the inside out talk
I’ve made a video of my talk, Git from the inside out.
The talk is a deep dive into the innards of Git. It focuses on the graph structure that underpins Git and the way the properties of this graph dictate Git’s behavior. It shows you how to use these properties to understand what Git has done, what it is doing, and what it will do.
If you’d rather digest the same information as six thousand words of prose, read my essay, Git from the inside out.
If you’d rather digest the same information as an implementation of Git in a thousand lines of heavily-annotated JavaScript, read my source code for Gitlet.
If you’d rather digest the same information in an interactive workshop, email me!
I've left the Recurse Center
After three joyous years, I’ve left the Recurse Center. I’ve moved to London to be closer to my family.
RC is like a writer’s retreat for programmers. Recursers come for three months to get significantly better at programming. The environment is mostly unstructured: there are no classes, curricula, grades or teachers. Instead, Recursers get better at programming by working on projects they choose.
My job had two parts.
First, I helped Recursers get better at programming. I helped them figure out what stuff they wanted to learn and helped them figure out what projects to work on to learn that stuff. I worked with Recursers on their projects: I gave code review, pair programmed, helped out in mammoth debugging sessions, helped plan program architectures. And I gave seminars on subjects that interested me.
Second, I worked on my own projects.
I made Code Lauren, a game programming environment for beginners. The user writes code for their game in a custom, easy-to-learn language. Their code runs on a virtual machine that lets them pause, step and rewind their program. This helps them understand control flow and debug their program. At BrooklynJS, I demoed Code Lauren and explained how it works.
I wrote Gitlet, an implementation of Git in one thousand lines of heavily-annotated JavaScript. From what I learned, I wrote a six-thousand-word deep dive into the innards of Git. I redesigned that material as a talk that I gave at Codecademy and !!Con.
I wrote Isla, an online programming environment for young children. The initial version was in Clojure and I later ported it to JavaScript. I talked about how it works at JSConf EU.
I livecoded Space Invaders in front of three-hundred people at Front-Trends. I turned the talk into a workshop that I gave at Strange Loop: How to build your first game in JavaScript.
I wrote A Practical Introduction to Functional Programming. I turned the essay into a workshop that I gave at RC.
I programmed a JavaScript game engine, Coquette, and used it to write three game prototypes: Racecar, Isla and Mary and Left Right Space.
I programmed a Lisp interpreter. I wrote an essay about how it works. I walked through the code in a talk at BrooklynJS.
I also wrote a bare-bones implementation of D3, an essay about testing, implementations of Asteroids, Lunar Lander and Snake, and a synth for the iPad in ClojureScript.
I did the best work of my life at RC. And I had the best time of my life at RC. I’m sad not to be able to program every day with Recursers. I’m sad not to be able to work on making RC the best place in the world to learn to program. And I’m sad to be parting from some dear friends.
I’ve learnt most of what I know about programming from Recursers. They helped me get better at code review, get better at explaining things and get better at pairing. They taught me both how and why to dive deep and how and why to be rigorous. They helped me try things that seemed too hard and helped me discover that they were hard but doable.
I’m currently thinking about what to work on next. My immediate plans are to go on a belated honeymoon with my wife, Lauren, to Paris, Florence and Berlin. I’m excited!
Git from the inside out
This essay explains how Git works. (If you’d rather absorb the same information as a talk, you can watch this video instead.)
The essay assumes you understand Git well enough to use it to version control your projects. It focuses on the graph structure that underpins Git and the way the properties of this graph dictate Git’s behavior. Looking at fundamentals, you build your mental model on the truth rather than on hypotheses constructed from evidence gathered while experimenting with the API. This truer model gives you a better understanding of what Git has done, what it is doing, and what it will do.
The text is structured as a series of Git commands run on a single project. At intervals, there are observations about the graph data structure that Git is built on. These observations illustrate a property of the graph and the behavior that this property produces.
After reading, if you wish to go even deeper into Git, you can look at the heavily annotated source code of my implementation of Git in JavaScript.
Create the project
~ $ mkdir alpha
~ $ cd alpha
The user creates alpha, a directory for their project.
~/alpha $ mkdir data
~/alpha $ printf 'a' > data/letter.txt
They move into the alpha directory and create a directory called data. Inside, they create a file called letter.txt that contains a. The alpha directory looks like this:
alpha
└── data
└── letter.txt
Initialize the repository
~/alpha $ git init
Initialized empty Git repository
git init makes the current directory into a Git repository. To do this, it creates a .git directory and writes some files to it. These files define everything about the Git configuration and the history of the project. They are just ordinary files. No magic in them. The user can read and edit them with a text editor or shell. Which is to say: the user can read and edit the history of their project as easily as their project files.
The alpha directory now looks like this:
alpha
├── data
| └── letter.txt
└── .git
├── objects
etc...
The .git directory and its contents are Git’s. All the other files are collectively known as the working copy. They are the user’s.
Add some files
~/alpha $ git add data/letter.txt
The user runs git add on data/letter.txt. This has two effects.
First, it creates a new blob file in the .git/objects/ directory.
This blob file contains the compressed content of data/letter.txt. Its name is derived by hashing its content. Hashing a piece of text means running a program on it that turns it into a smaller1 piece of text that uniquely2 identifies the original. For example, Git hashes a to 2e65efe2a145dda7ee51d1741299f848e5bf752e. The first two characters are used as the name of a directory inside the objects database: .git/objects/2e/. The rest of the hash is used as the name of the blob file that holds the content of the added file: .git/objects/2e/65efe2a145dda7ee51d1741299f848e5bf752e.
Notice how just adding a file to Git saves its content to the objects directory. Its content will still be safe inside Git if the user deletes data/letter.txt from the working copy.
Second, git add adds the file to the index. The index is a list that contains every file that Git has been told to keep track of. It is stored as a file at .git/index. Each line of the file maps a tracked file to the hash of its content at the moment it was added. This is the index after the git add command is run:
data/letter.txt 2e65efe2a145dda7ee51d1741299f848e5bf752e
The user makes a file called data/number.txt that contains 1234.
~/alpha $ printf '1234' > data/number.txt
The working copy looks like this:
alpha
└── data
└── letter.txt
└── number.txt
The user adds the file to Git.
~/alpha $ git add data
The git add command creates a blob object that contains the content of data/number.txt. It adds an index entry for data/number.txt that points at the blob. This is the index after the git add command is run a second time:
data/letter.txt 2e65efe2a145dda7ee51d1741299f848e5bf752e
data/number.txt 274c0052dd5408f8ae2bc8440029ff67d79bc5c3
Notice that only the files in the data directory are listed in the index, though the user ran git add data. The data directory is not listed separately.
~/alpha $ printf '1' > data/number.txt
~/alpha $ git add data
When the user originally created data/number.txt, they meant to type 1, not 1234. They make the correction and add the file to the index again. This command creates a new blob with the new content. And it updates the index entry for data/number.txt to point at the new blob.
Make a commit
~/alpha $ git commit -m 'a1'
[master (root-commit) 774b54a] a1
The user makes the a1 commit. Git prints some data about the commit. These data will make sense shortly.
The commit command has three steps. It creates a tree graph to represent the content of the version of the project being committed. It creates a commit object. It points the current branch at the new commit object.
Create a tree graph
Git records the current state of the project by creating a tree graph from the index. This tree graph records the location and content of every file in the project.
The graph is composed of two types of object: blobs and trees.
Blobs are stored by git add. They represent the content of files.
Trees are stored when a commit is made. A tree represents a directory in the working copy.
Below is the tree object that records the contents of the data directory for the new commit:
100664 blob 2e65efe2a145dda7ee51d1741299f848e5bf752e letter.txt
100664 blob 56a6051ca2b02b04ef92d5150c9ef600403cb1de number.txt
The first line records everything required to reproduce data/letter.txt. The first part states the file’s permissions. The second part states that the content of this entry is represented by a blob, rather than a tree. The third part states the hash of the blob. The fourth part states the file’s name.
The second line records the same for data/number.txt.
Below is the tree object for alpha, which is the root directory of the project:
040000 tree 0eed1217a2947f4930583229987d90fe5e8e0b74 data
The sole line in this tree points at the data tree.

In the graph above, the root tree points at the data tree. The data tree points at the blobs for data/letter.txt and data/number.txt.
Create a commit object
git commit creates a commit object after creating the tree graph. The commit object is just another text file in .git/objects/:
tree ffe298c3ce8bb07326f888907996eaa48d266db4
author Mary Rose Cook <mary@maryrosecook.com> 1424798436 -0500
committer Mary Rose Cook <mary@maryrosecook.com> 1424798436 -0500
a1
The first line points at the tree graph. The hash is for the tree object that represents the root of the working copy. That is: the alpha directory. The last line is the commit message.

Point the current branch at the new commit
Finally, the commit command points the current branch at the new commit object.
Which is the current branch? Git goes to the HEAD file at .git/HEAD and finds:
ref: refs/heads/master
This says that HEAD is pointing at master. master is the current branch.
HEAD and master are both refs. A ref is a label used by Git or the user to identify a specific commit.
The file that represents the master ref does not exist, because this is the first commit to the repository. Git creates the file at .git/refs/heads/master and sets its content to the hash of the commit object:
74ac3ad9cde0b265d2b4f1c778b283a6e2ffbafd
(If you are typing in these Git commands as you read, the hash of your a1 commit will be different from the hash of mine. Content objects like blobs and trees always hash to the same value. Commits do not, because they include dates and the names of their creators.)
Let’s add HEAD and master to the Git graph:
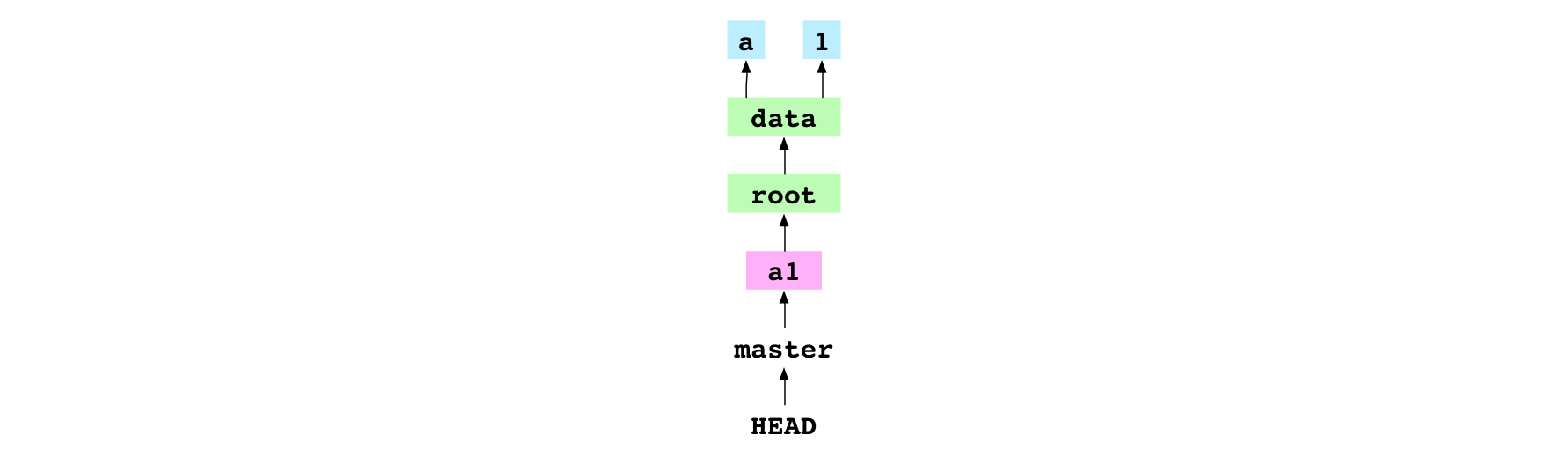
HEAD points at master, as it did before the commit. But master now exists and points at the new commit object.
Make a commit that is not the first commit
Below is the Git graph after the a1 commit. The working copy and index are included.
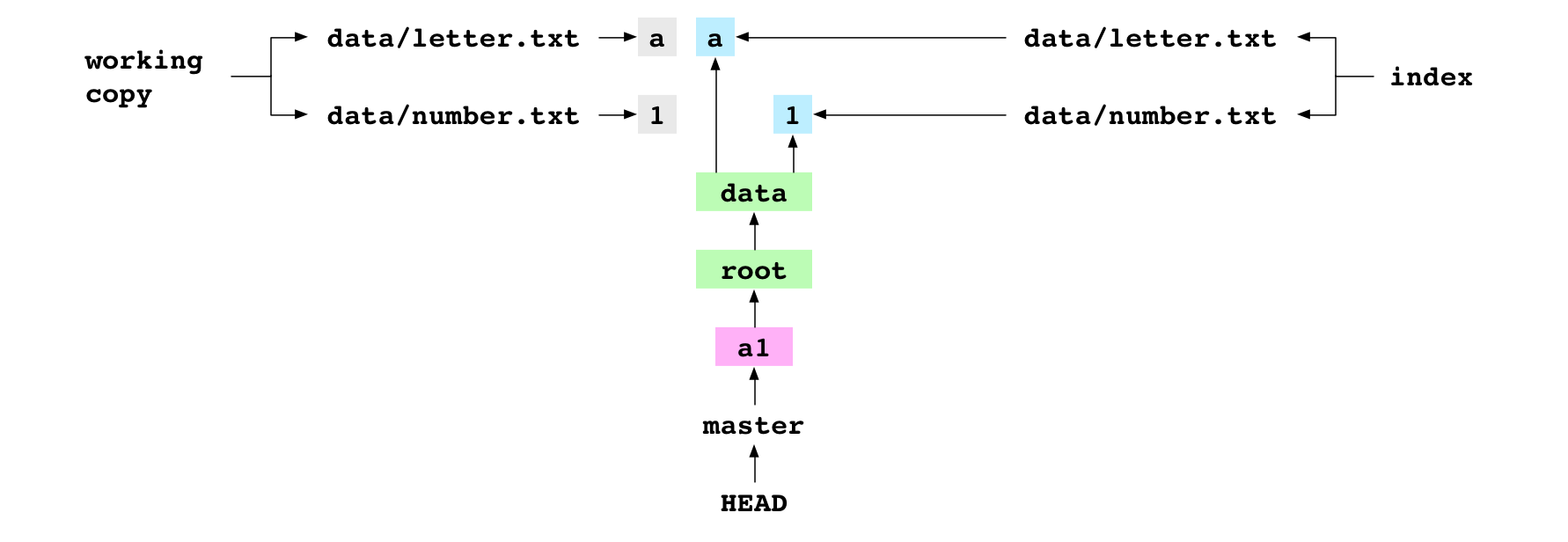
Notice that the working copy, index, and a1 commit all have the same content for data/letter.txt and data/number.txt. The index and HEAD commit both use hashes to refer to blob objects, but the working copy content is stored as text in a different place.
~/alpha $ printf '2' > data/number.txt
The user sets the content of data/number.txt to 2. This updates the working copy, but leaves the index and HEAD commit as they are.
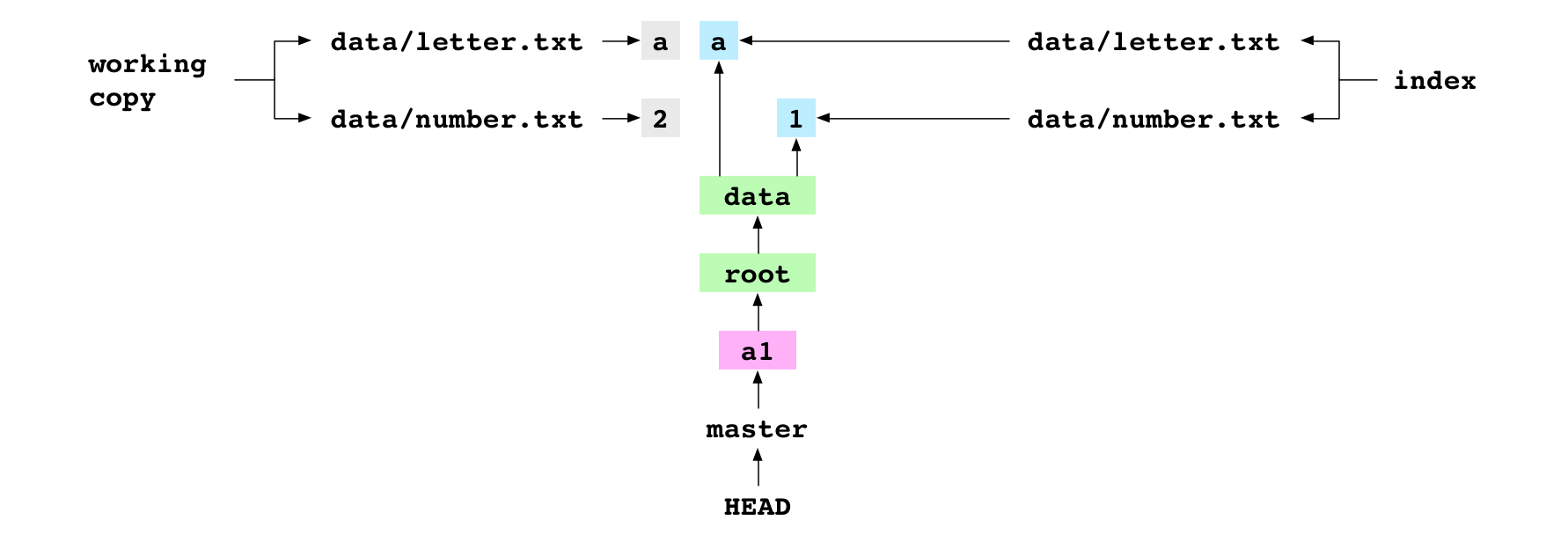
~/alpha $ git add data/number.txt
The user adds the file to Git. This adds a blob containing 2 to the objects directory. It points the index entry for data/number.txt at the new blob.
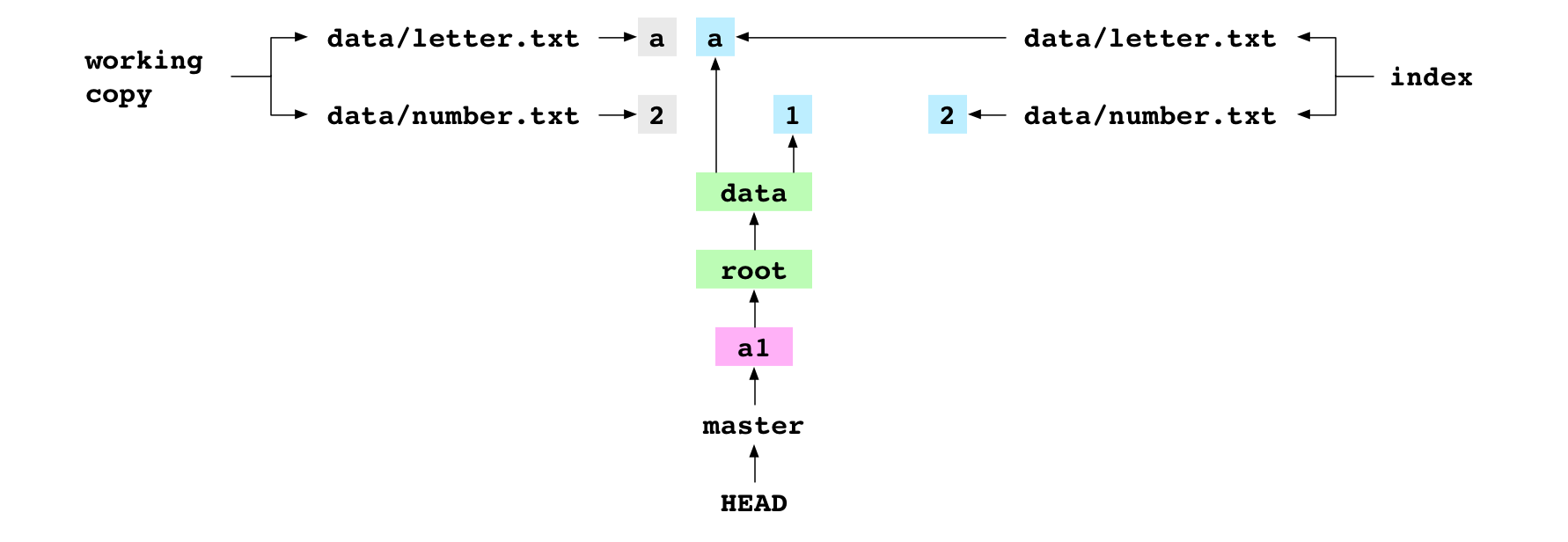
~/alpha $ git commit -m 'a2'
[master f0af7e6] a2
The user commits. The steps for the commit are the same as before.
First, a new tree graph is created to represent the content of the index.
The index entry for data/number.txt has changed. The old data tree no longer reflects the indexed state of the data directory. A new data tree object must be created:
100664 blob 2e65efe2a145dda7ee51d1741299f848e5bf752e letter.txt
100664 blob d8263ee9860594d2806b0dfd1bfd17528b0ba2a4 number.txt
The new data tree hashes to a different value from the old data tree. A new root tree must be created to record this hash:
040000 tree 40b0318811470aaacc577485777d7a6780e51f0b data
Second, a new commit object is created.
tree ce72afb5ff229a39f6cce47b00d1b0ed60fe3556
parent 774b54a193d6cfdd081e581a007d2e11f784b9fe
author Mary Rose Cook <mary@maryrosecook.com> 1424813101 -0500
committer Mary Rose Cook <mary@maryrosecook.com> 1424813101 -0500
a2
The first line of the commit object points at the new root tree object. The second line points at a1: the commit’s parent. To find the parent commit, Git went to HEAD, followed it to master and found the commit hash of a1.
Third, the content of the master branch file is set to the hash of the new commit.
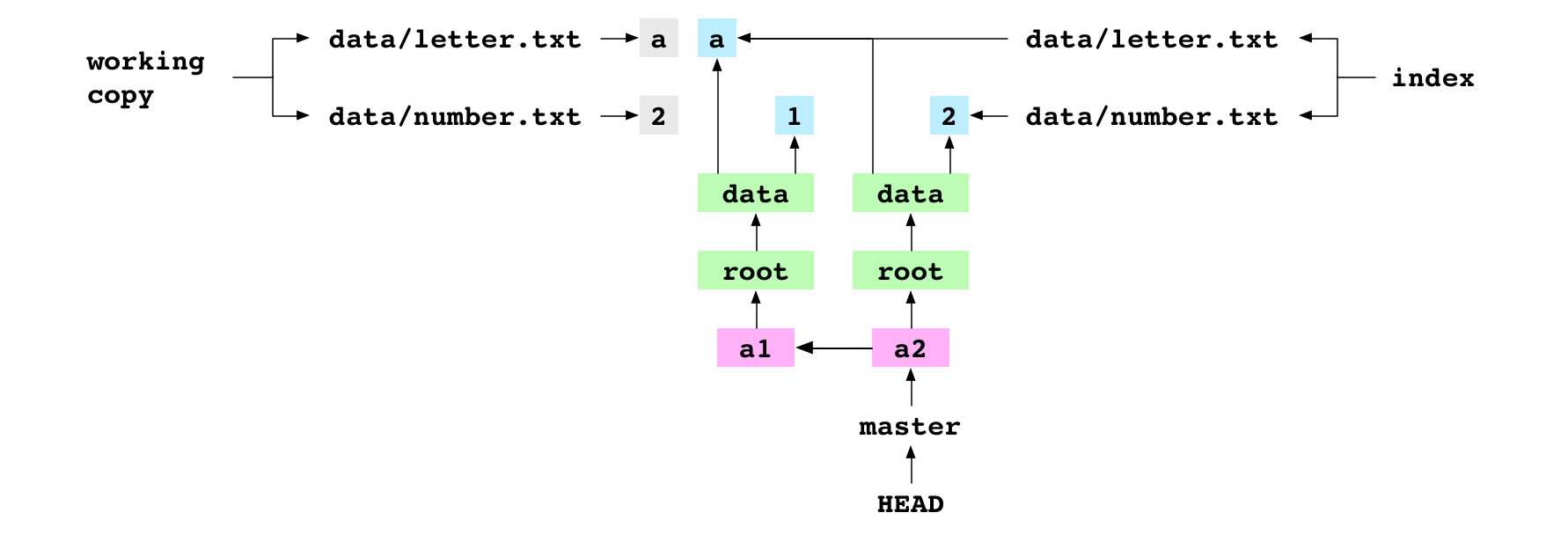
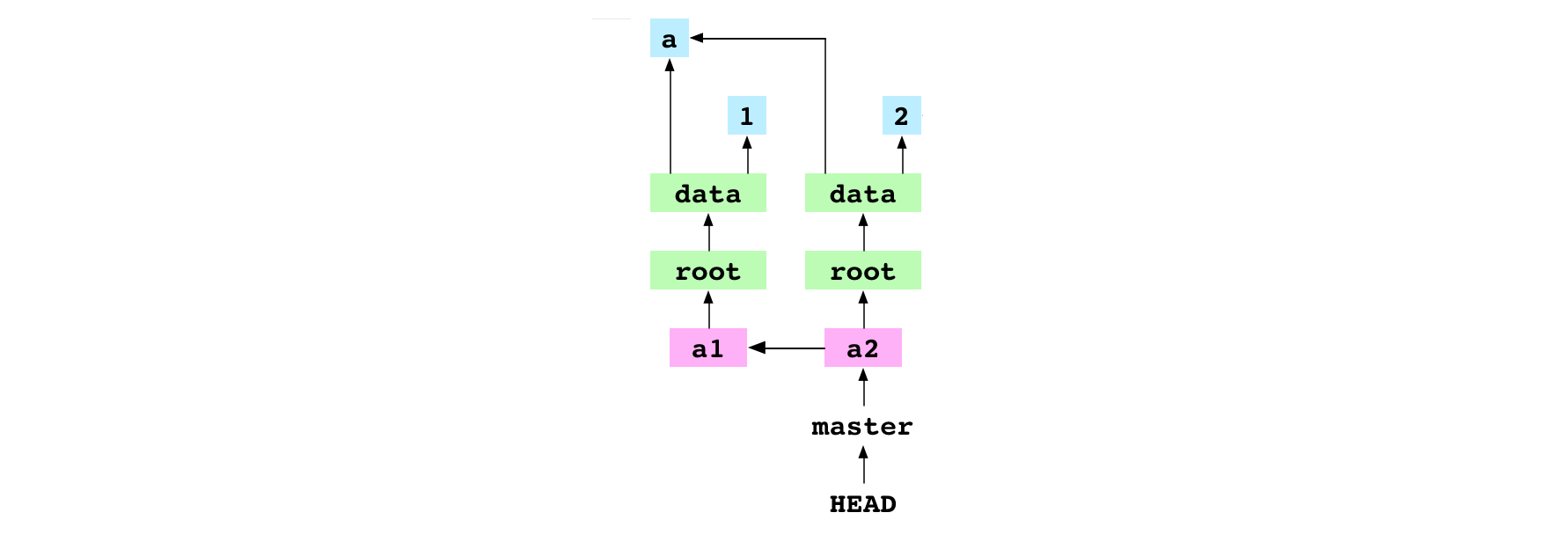
Graph property: content is stored as a tree of objects. This means that only diffs are stored in the objects database. Look at the graph above. The a2 commit reuses the a blob that was made before the a1 commit. Similarly, if a whole directory doesn’t change from commit to commit, its tree and all the blobs and trees below it can be reused. Generally, there are few content changes from commit to commit. This means that Git can store large commit histories in a small amount of space.
Graph property: each commit has a parent. This means that a repository can store the history of a project.
Graph property: refs are entry points to one part of the commit history or another. This means that commits can be given meaningful names. The user organizes their work into lineages that are meaningful to their project with concrete refs like fix-for-bug-376. Git uses symbolic refs like HEAD, MERGE_HEAD and FETCH_HEAD to support commands that manipulate the commit history.
Graph property: the nodes in the objects/ directory are immutable. This means that content is edited, not deleted. Every piece of content ever added and every commit ever made is somewhere in the objects directory3.
Graph property: refs are mutable. Therefore, the meaning of a ref can change. The commit that master points at might be the best version of a project at the moment, but, soon enough, it will be superseded by a newer and better commit.
Graph property: the working copy and the commits pointed at by refs are readily available, but other commits are not. This means that recent history is easier to recall, but that it also changes more often. Or: Git has a fading memory that must be jogged with increasingly vicious prods.
The working copy is the easiest point in history to recall because it is in the root of the repository. Recalling it doesn’t even require a Git command. It is also the least permanent point in history. The user can make a dozen versions of a file but Git won’t record any of them unless they are added.
The commit that HEAD points at is very easy to recall. It is at the tip of the branch that is checked out. To see its content, the user can just stash4 and then examine the working copy. At the same time, HEAD is the most frequently changing ref.
The commit that a concrete ref points at is easy to recall. The user can simply check out that branch. The tip of a branch changes less often than HEAD, but often enough for the meaning of a branch name to be changeable.
It is difficult to recall a commit that is not pointed at by any ref. The further the user goes from a ref, the harder it will be for them to construct the meaning of a commit. But the further back they go, the less likely it is that someone will have changed history since they last looked5.
Check out a commit
~/alpha $ git checkout 37888c2
You are in 'detached HEAD' state...
The user checks out the a2 commit using its hash. (If you are running these Git commands, this one won’t work. Use git log to find the hash of your a2 commit.)
Checking out has four steps.
First, Git gets the a2 commit and gets the tree graph it points at.
Second, it writes the file entries in the tree graph to the working copy. This results in no changes. The working copy already has the content of the tree graph being written to it because HEAD was already pointing via master at the a2 commit.
Third, Git writes the file entries in the tree graph to the index. This, too, results in no changes. The index already has the content of the a2 commit.
Fourth, the content of HEAD is set to the hash of the a2 commit:
f0af7e62679e144bb28c627ee3e8f7bdb235eee9
Setting the content of HEAD to a hash puts the repository in the detached HEAD state. Notice in the graph below that HEAD points directly at the a2 commit, rather than pointing at master.
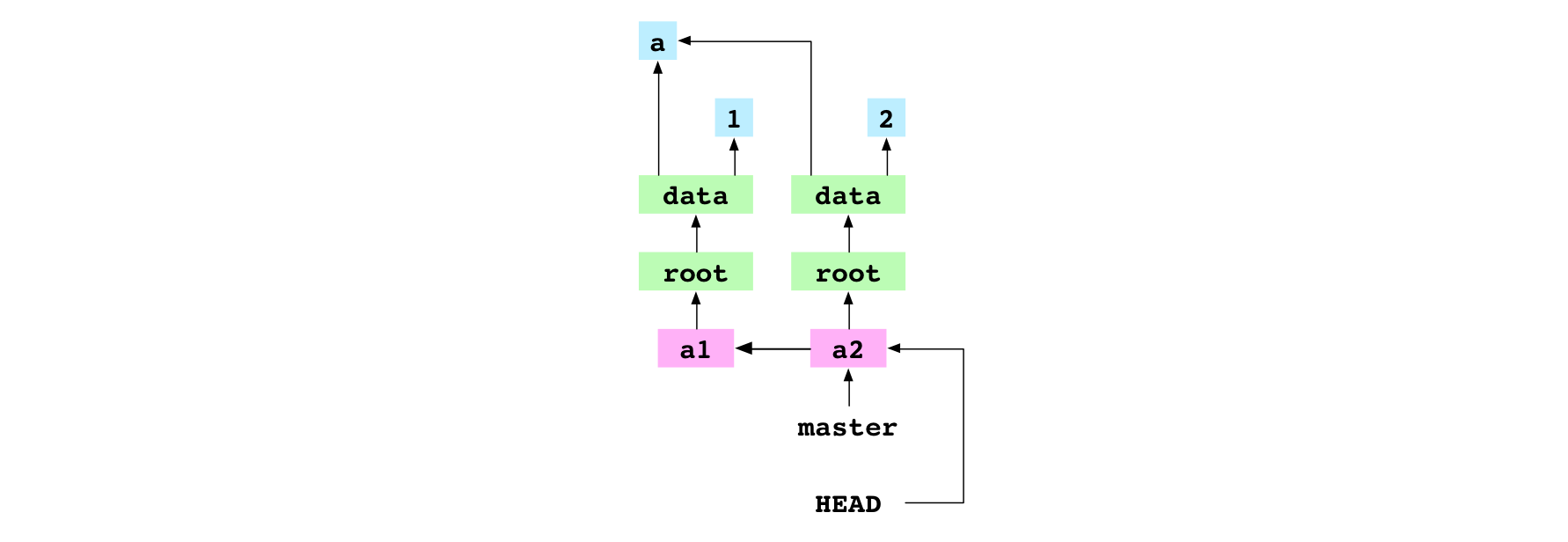
~/alpha $ printf '3' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'a3'
[detached HEAD 3645a0e] a3
The user sets the content of data/number.txt to 3 and commits the change. Git goes to HEAD to get the parent of the a3 commit. Instead of finding and following a branch ref, it finds and returns the hash of the a2 commit.
Git updates HEAD to point directly at the hash of the new a3 commit. The repository is still in the detached HEAD state. The commit is not on a branch because no branch ref points at either a3 or one of its descendants. This means it is easy to lose.
From now on, trees and blobs will mostly be omitted from the graph diagrams.
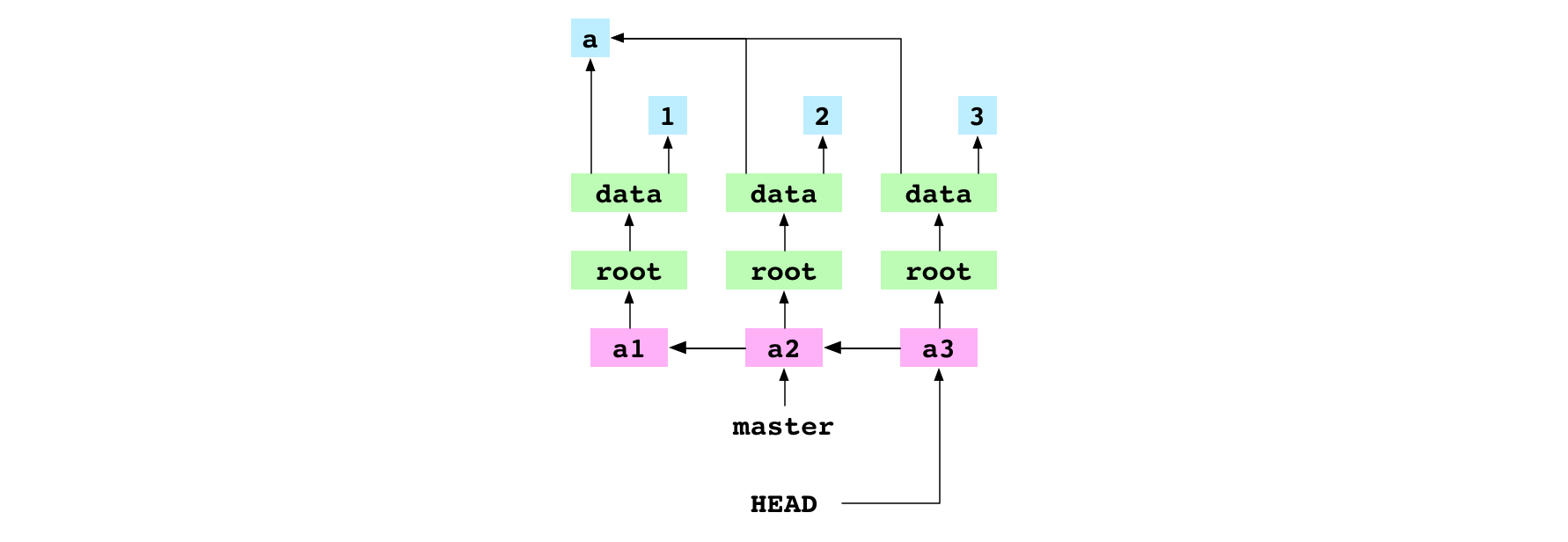
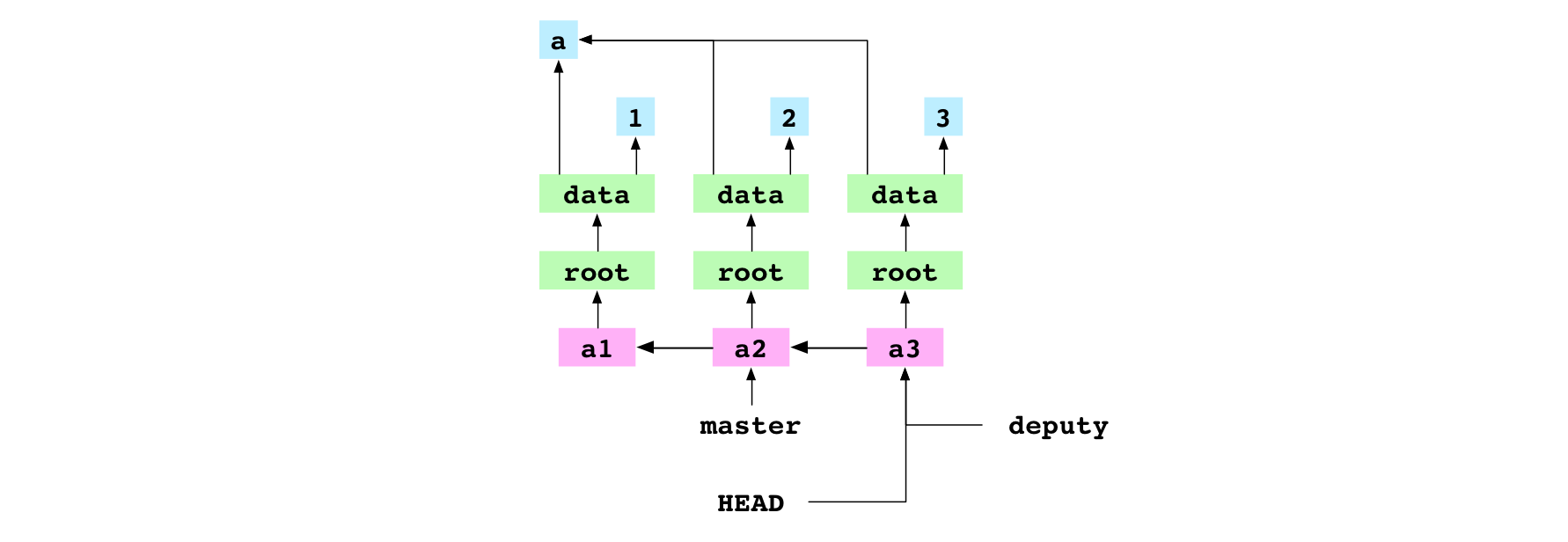
Create a branch
~/alpha $ git branch deputy
The user creates a new branch called deputy. This just creates a new file at .git/refs/heads/deputy that contains the hash that HEAD is pointing at: the hash of the a3 commit.
Graph property: branches are just refs and refs are just files. This means that Git branches are lightweight.
The creation of the deputy branch puts the new a3 commit safely on a branch. HEAD is still detached because it still points directly at a commit.
Check out a branch
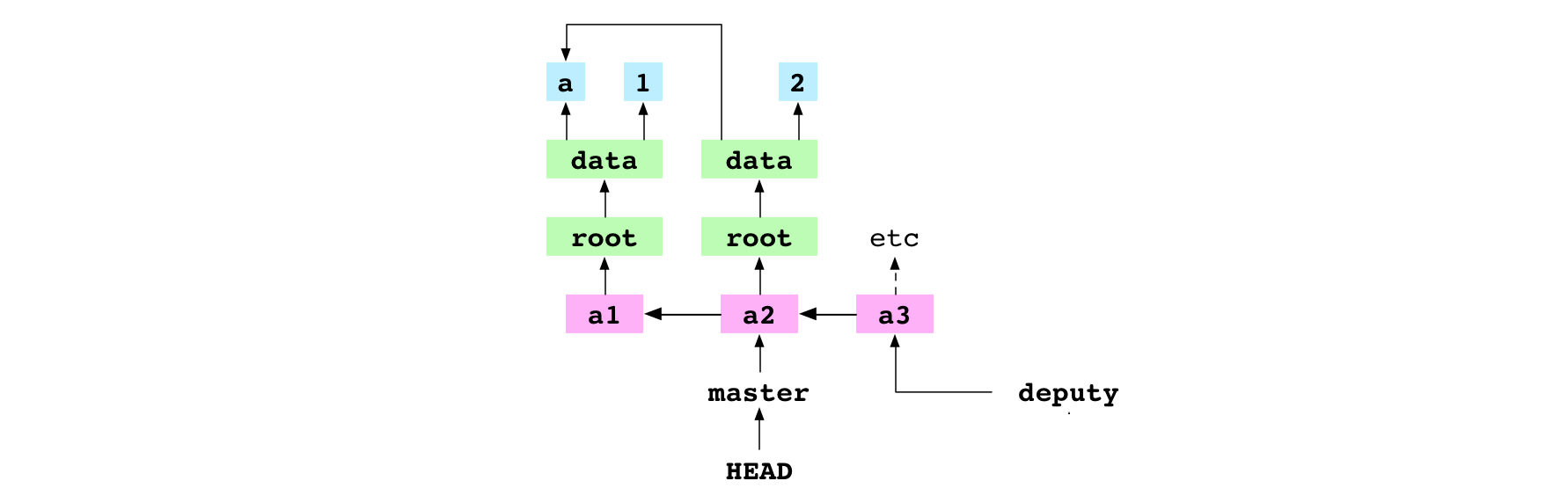
~/alpha $ git checkout master
Switched to branch 'master'
The user checks out the master branch.
First, Git gets the a2 commit that master points at and gets the tree graph the commit points at.
Second, Git writes the file entries in the tree graph to the files of the working copy. This sets the content of data/number.txt to 2.
Third, Git writes the file entries in the tree graph to the index. This updates the entry for data/number.txt to the hash of the 2 blob.
Fourth, Git points HEAD at master by changing its content from a hash to:
ref: refs/heads/master
Check out a branch that is incompatible with the working copy
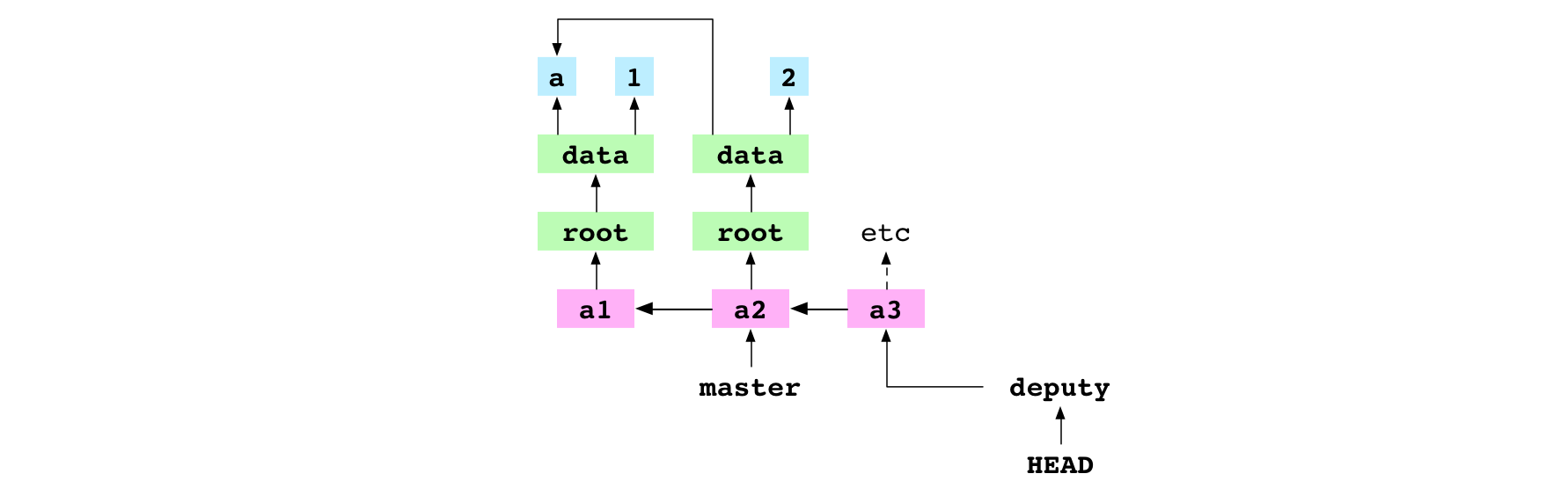
~/alpha $ printf '789' > data/number.txt
~/alpha $ git checkout deputy
Your changes to these files would be overwritten
by checkout:
data/number.txt
Commit your changes or stash them before you
switch branches.
The user accidentally sets the content of data/number.txt to 789. They try to check out deputy. Git prevents the check out.
HEAD points at master which points at a2 where data/number.txt reads 2. deputy points at a3 where data/number.txt reads 3. The working copy version of data/number.txt reads 789. All these versions are different and the differences must be resolved.
Git could replace the working copy version of data/number.txt with the version in the commit being checked out. But it avoids data loss at all costs.
Git could merge the working copy version with the version being checked out. But this is complicated.
So, Git aborts the check out.
~/alpha $ printf '2' > data/number.txt
~/alpha $ git checkout deputy
Switched to branch 'deputy'
The user notices that they accidentally edited data/number.txt and sets the content back to 2. They check out deputy successfully.
Merge an ancestor
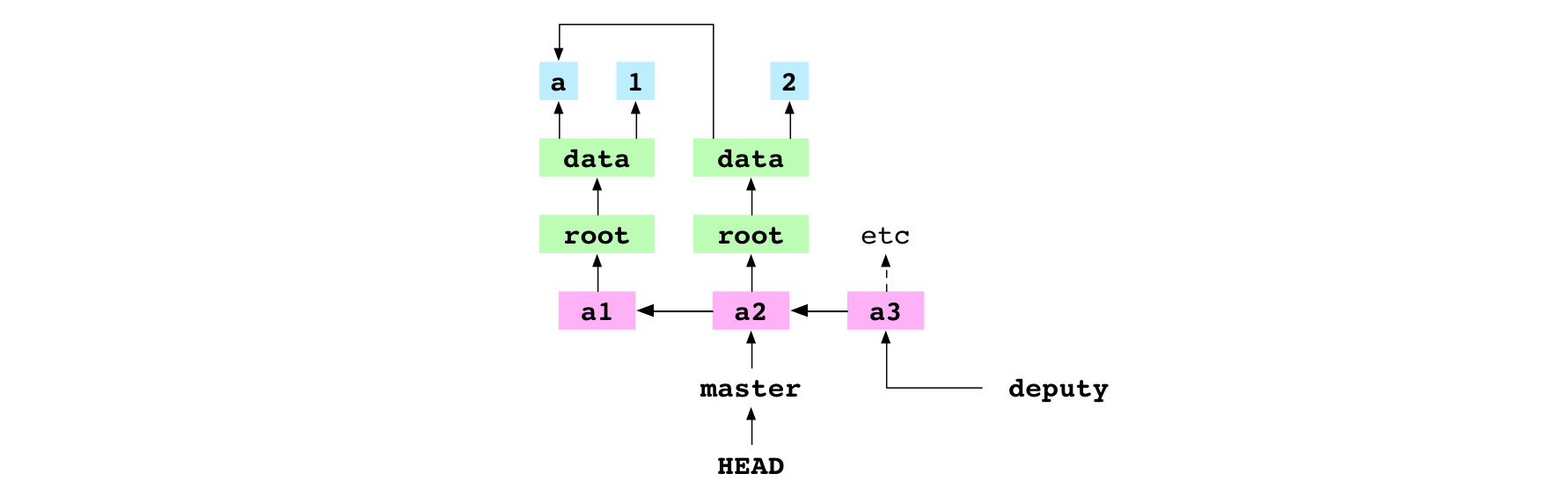
~/alpha $ git merge master
Already up-to-date.
The user merges master into deputy. Merging two branches means merging two commits. The first commit is the one that deputy points at: the receiver. The second commit is the one that master points at: the giver. For this merge, Git does nothing. It reports it is Already up-to-date..
Graph property: the series of commits in the graph are interpreted as a series of changes made to the content of the repository. This means that, in a merge, if the giver commit is an ancestor of the receiver commit, Git will do nothing. Those changes have already been incorporated.
Merge a descendent
~/alpha $ git checkout master
Switched to branch 'master'
The user checks out master.
~/alpha $ git merge deputy
Fast-forward
They merge deputy into master. Git discovers that the receiver commit, a2, is an ancestor of the giver commit, a3. It can do a fast-forward merge.
It gets the giver commit and gets the tree graph that it points at. It writes the file entries in the tree graph to the working copy and the index. It “fast-forwards” master to point at a3.
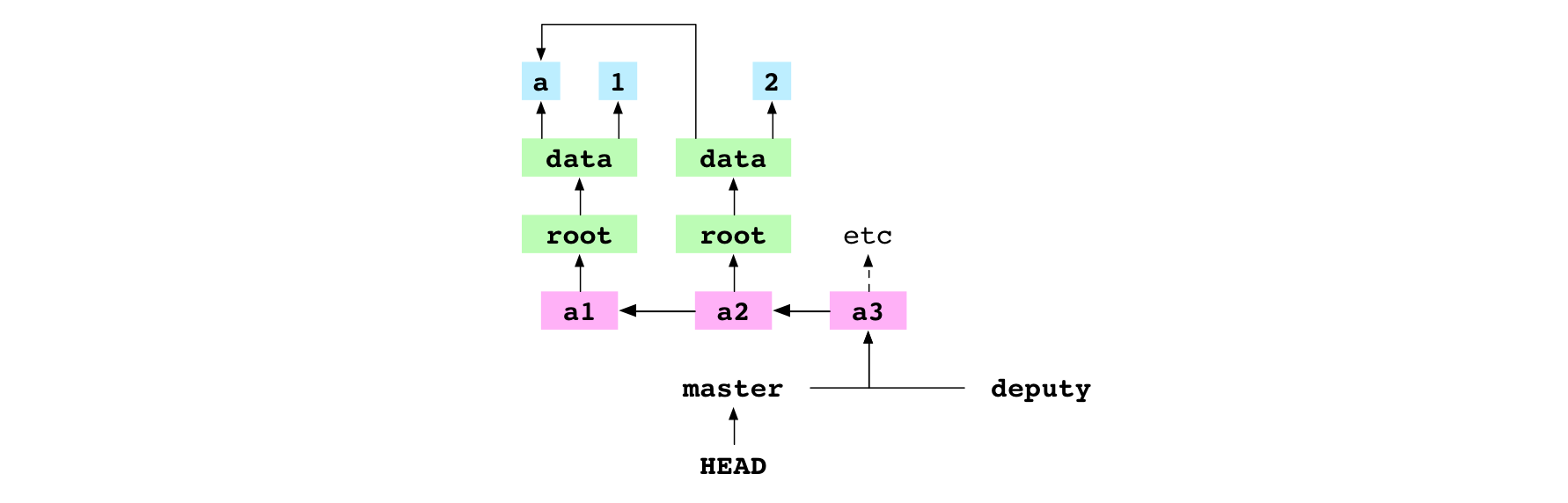
Graph property: the series of commits in the graph are interpreted as a series of changes made to the content of the repository. This means that, in a merge, if the giver is a descendent of the receiver, history is not changed. There is already a sequence of commits that describe the change to make: the sequence of commits between the receiver and the giver. But, though the Git history doesn’t change, the Git graph does change. The concrete ref that HEAD points at is updated to point at the giver commit.
Merge two commits from different lineages
~/alpha $ printf '4' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'a4'
[master 7b7bd9a] a4
The user sets the content of number.txt to 4 and commits the change to master.
~/alpha $ git checkout deputy
Switched to branch 'deputy'
~/alpha $ printf 'b' > data/letter.txt
~/alpha $ git add data/letter.txt
~/alpha $ git commit -m 'b3'
[deputy 982dffb] b3
The user checks out deputy. They set the content of data/letter.txt to b and commit the change to deputy.
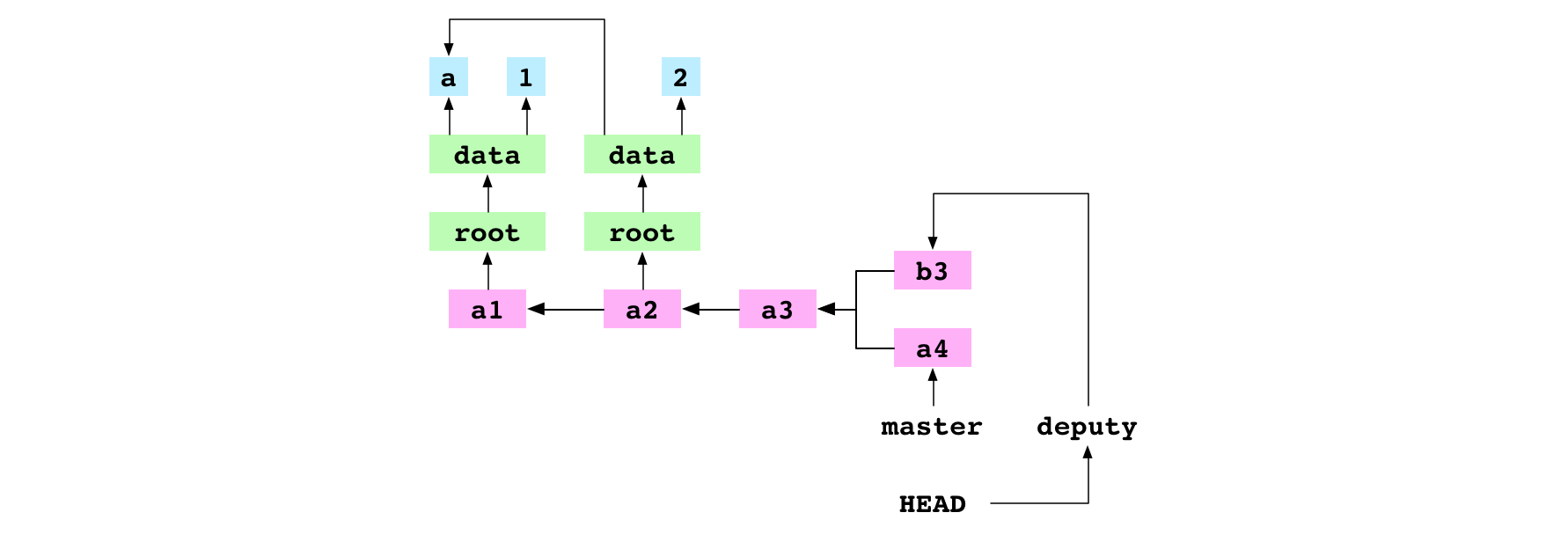
Graph property: commits can share parents. This means that new lineages can be created in the commit history.
Graph property: commits can have multiple parents. This means that separate lineages can be joined by a commit with two parents: a merge commit.
~/alpha $ git merge master -m 'b4'
Merge made by the 'recursive' strategy.
The user merges master into deputy.
Git discovers that the receiver, b3, and the giver, a4, are in different lineages. It makes a merge commit. This process has eight steps.
First, Git writes the hash of the giver commit to a file at alpha/.git/MERGE_HEAD. The presence of this file tells Git it is in the middle of merging.
Second, Git finds the base commit: the most recent ancestor that the receiver and giver commits have in common.
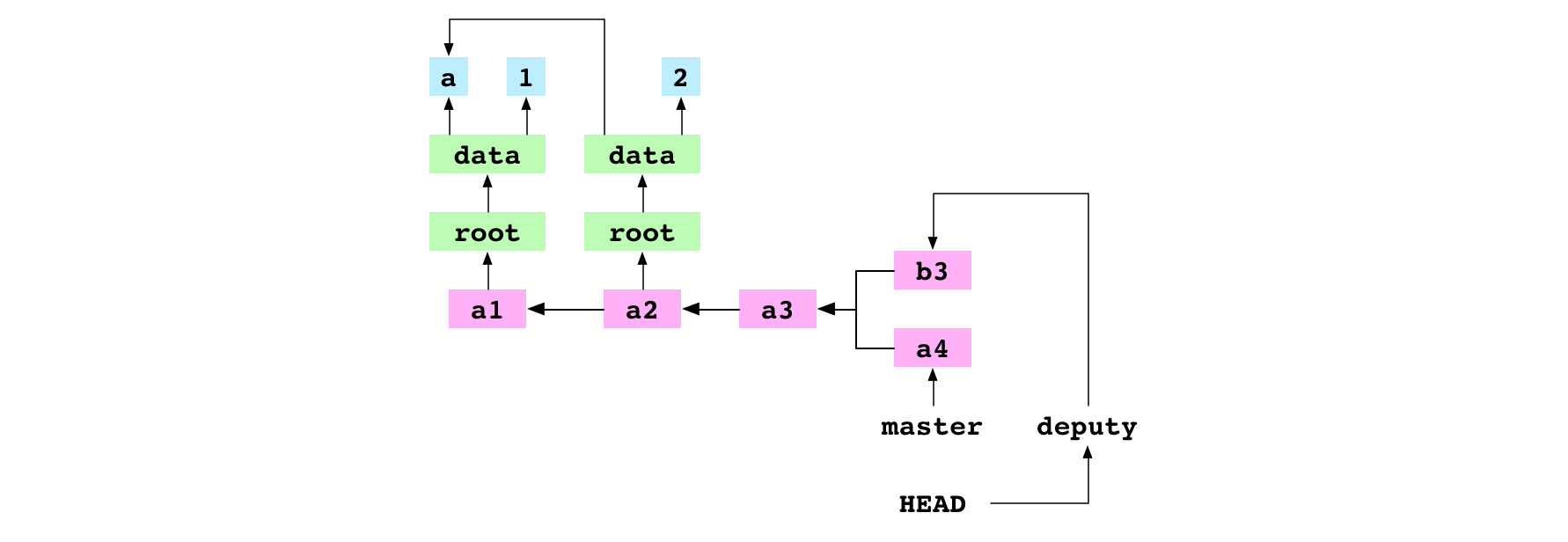
Graph property: commits have parents. This means that it is possible to find the point at which two lineages diverged. Git traces backwards from b3 to find all its ancestors and backwards from a4 to find all its ancestors. It finds the most recent ancestor shared by both lineages, a3. This is the base commit.
Third, Git generates the indices for the base, receiver and giver commits from their tree graphs.
Fourth, Git generates a diff that combines the changes made to the base by the receiver commit and the giver commit. This diff is a list of file paths that point to a change: add, remove, modify or conflict.
Git gets the list of all the files that appear in the base, receiver or giver indices. For each one, it compares the index entries to decide the change to make to the file. It writes a corresponding entry to the diff. In this case, the diff has two entries.
The first entry is for data/letter.txt. The content of this file is a in the base, b in the receiver and a in the giver. The content is different in the base and receiver. But it is the same in the base and giver. Git sees that the content was modified by the receiver, but not the giver. The diff entry for data/letter.txt is a modification, not a conflict.
The second entry in the diff is for data/number.txt. In this case, the content is the same in the base and receiver, and different in the giver. The diff entry for data/letter.txt is also a modification.
Graph property: it is possible to find the base commit of a merge. This means that, if a file has changed from the base in just the receiver or giver, Git can automatically resolve the merge of that file. This reduces the work the user must do.
Fifth, the changes indicated by the entries in the diff are applied to the working copy. The content of data/letter.txt is set to b and the content of data/number.txt is set to 4.
Sixth, the changes indicated by the entries in the diff are applied to the index. The entry for data/letter.txt is pointed at the b blob and the entry for data/number.txt is pointed at the 4 blob.
Seventh, the updated index is committed:
tree 20294508aea3fb6f05fcc49adaecc2e6d60f7e7d
parent 982dffb20f8d6a25a8554cc8d765fb9f3ff1333b
parent 7b7bd9a5253f47360d5787095afc5ba56591bfe7
author Mary Rose Cook <mary@maryrosecook.com> 1425596551 -0500
committer Mary Rose Cook <mary@maryrosecook.com> 1425596551 -0500
b4
Notice that the commit has two parents.
Eighth, Git points the current branch, deputy, at the new commit.
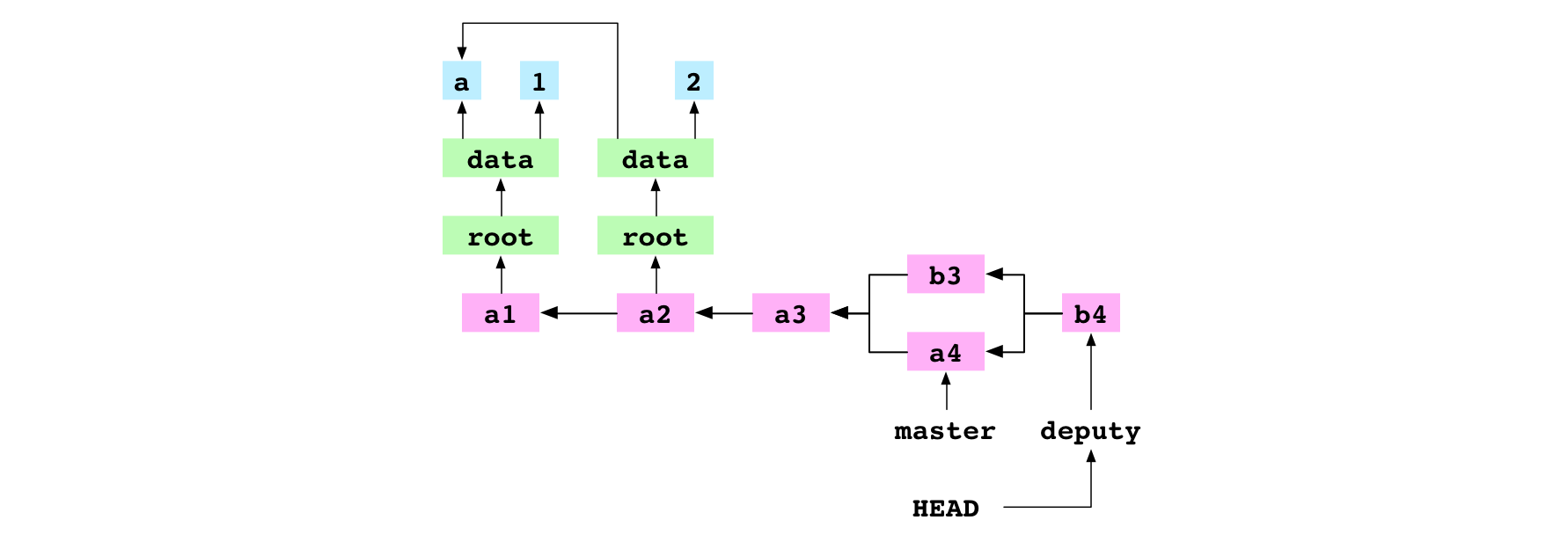
Merge two commits from different lineages that both modify the same file
~/alpha $ git checkout master
Switched to branch 'master'
~/alpha $ git merge deputy
Fast-forward
The user checks out master. They merge deputy into master. This fast-forwards master to the b4 commit. master and deputy now point at the same commit.
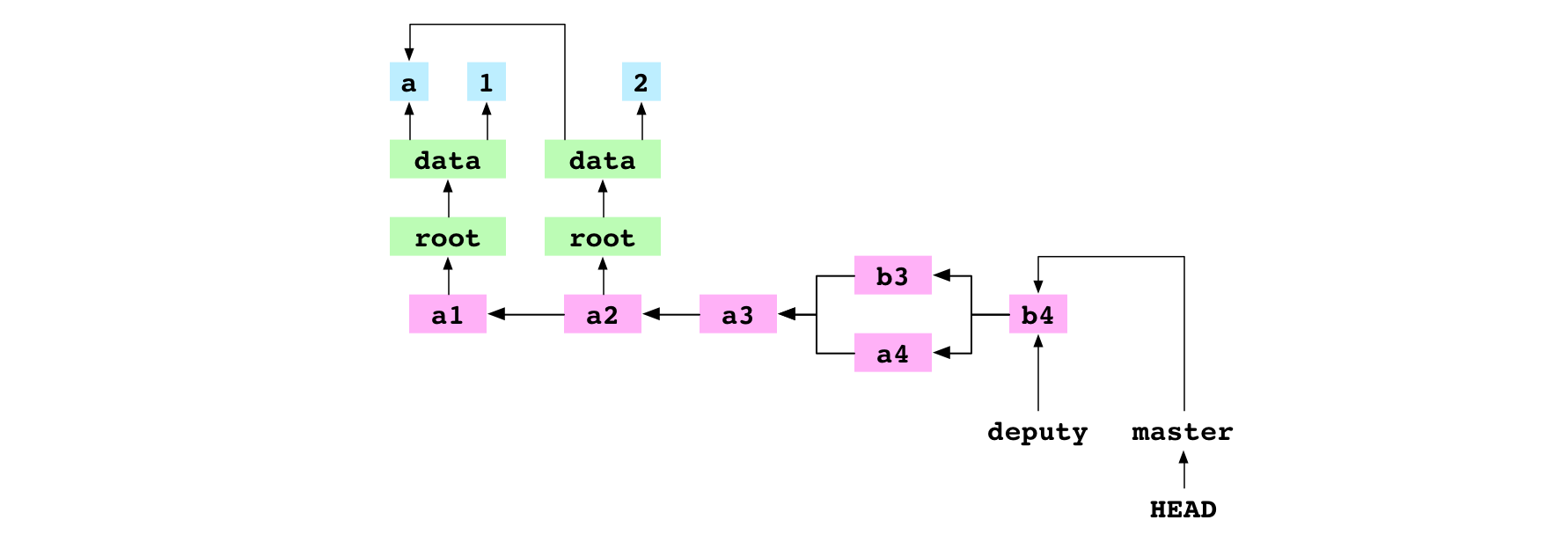
~/alpha $ git checkout deputy
Switched to branch 'deputy'
~/alpha $ printf '5' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'b5'
[deputy bd797c2] b5
The user checks out deputy. They set the content of data/number.txt to 5 and commit the change to deputy.
~/alpha $ git checkout master
Switched to branch 'master'
~/alpha $ printf '6' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'b6'
[master 4c3ce18] b6
The user checks out master. They set the content of data/number.txt to 6 and commit the change to master.
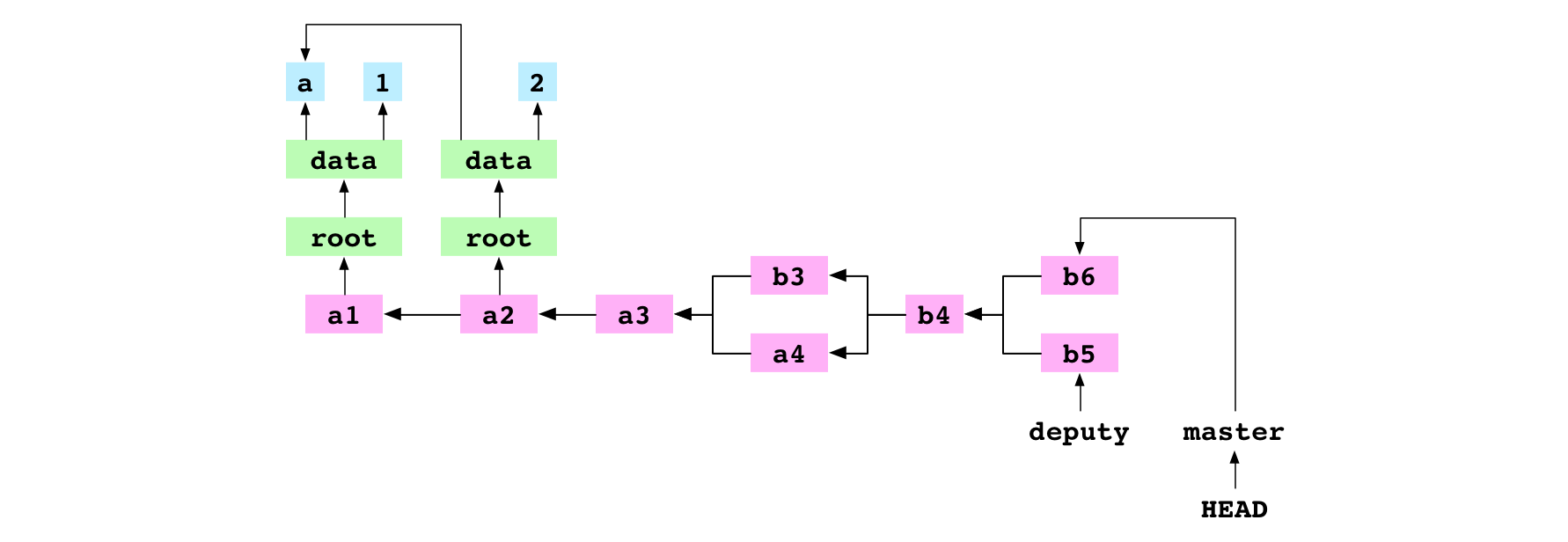
~/alpha $ git merge deputy
CONFLICT in data/number.txt
Automatic merge failed; fix conflicts and
commit the result.
The user merges deputy into master. There is a conflict and the merge is paused. The process for a conflicted merge follows the same first six steps as the process for an unconflicted merge: set .git/MERGE_HEAD, find the base commit, generate the indices of the base, receiver and giver commits, create a diff, update the working copy and update the index. Because of the conflict, the seventh commit step and eighth ref update step are never taken. Let’s go through the steps again and see what happens.
First, Git writes the hash of the giver commit to a file at .git/MERGE_HEAD.
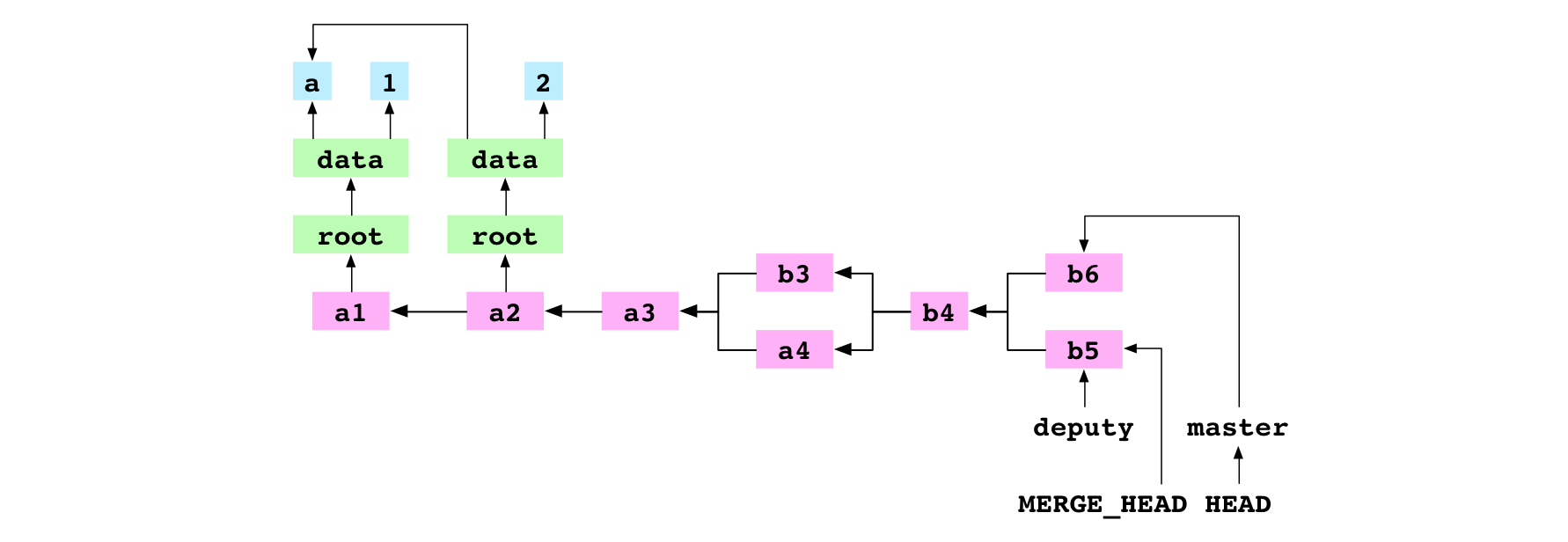
Second, Git finds the base commit, b4.
Third, Git generates the indices for the base, receiver and giver commits.
Fourth, Git generates a diff that combines the changes made to the base by the receiver commit and the giver commit. This diff is a list of file paths that point to a change: add, remove, modify or conflict.
In this case, the diff contains only one entry: data/number.txt. The entry is marked as a conflict because the content for data/number.txt is different in the receiver, giver and base.
Fifth, the changes indicated by the entries in the diff are applied to the working copy. For a conflicted area, Git writes both versions to the file in the working copy. The content of data/number.txt is set to:
<<<<<<< HEAD
6
=======
5
>>>>>>> deputy
Sixth, the changes indicated by the entries in the diff are applied to the index. Entries in the index are uniquely identified by a combination of their file path and stage. The entry for an unconflicted file has a stage of 0. Before this merge, the index looked like this, where the 0s are stage values:
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748
0 data/number.txt 62f9457511f879886bb7728c986fe10b0ece6bcb
After the merge diff is written to the index, the index looks like this:
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748
1 data/number.txt bf0d87ab1b2b0ec1a11a3973d2845b42413d9767
2 data/number.txt 62f9457511f879886bb7728c986fe10b0ece6bcb
3 data/number.txt 7813681f5b41c028345ca62a2be376bae70b7f61
The entry for data/letter.txt at stage 0 is the same as it was before the merge. The entry for data/number.txt at stage 0 is gone. There are three new entries in its place. The entry for stage 1 has the hash of the base data/number.txt content. The entry for stage 2 has the hash of the receiver data/number.txt content. The entry for stage 3 has the hash of the giver data/number.txt content. The presence of these three entries tells Git that data/number.txt is in conflict.
The merge pauses.
~/alpha $ printf '11' > data/number.txt
~/alpha $ git add data/number.txt
The user integrates the content of the two conflicting versions by setting the content of data/number.txt to 11. They add the file to the index. Git adds a blob containing 11. Adding a conflicted file tells Git that the conflict is resolved. Git removes the data/number.txt entries for stages 1, 2 and 3 from the index. It adds an entry for data/number.txt at stage 0 with the hash of the new blob. The index now reads:
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748
0 data/number.txt 9d607966b721abde8931ddd052181fae905db503
~/alpha $ git commit -m 'b11'
[master 251a513] b11
Seventh, the user commits. Git sees .git/MERGE_HEAD in the repository, which tells it that a merge is in progress. It checks the index and finds there are no conflicts. It creates a new commit, b11, to record the content of the resolved merge. It deletes the file at .git/MERGE_HEAD. This completes the merge.
Eighth, Git points the current branch, master, at the new commit.
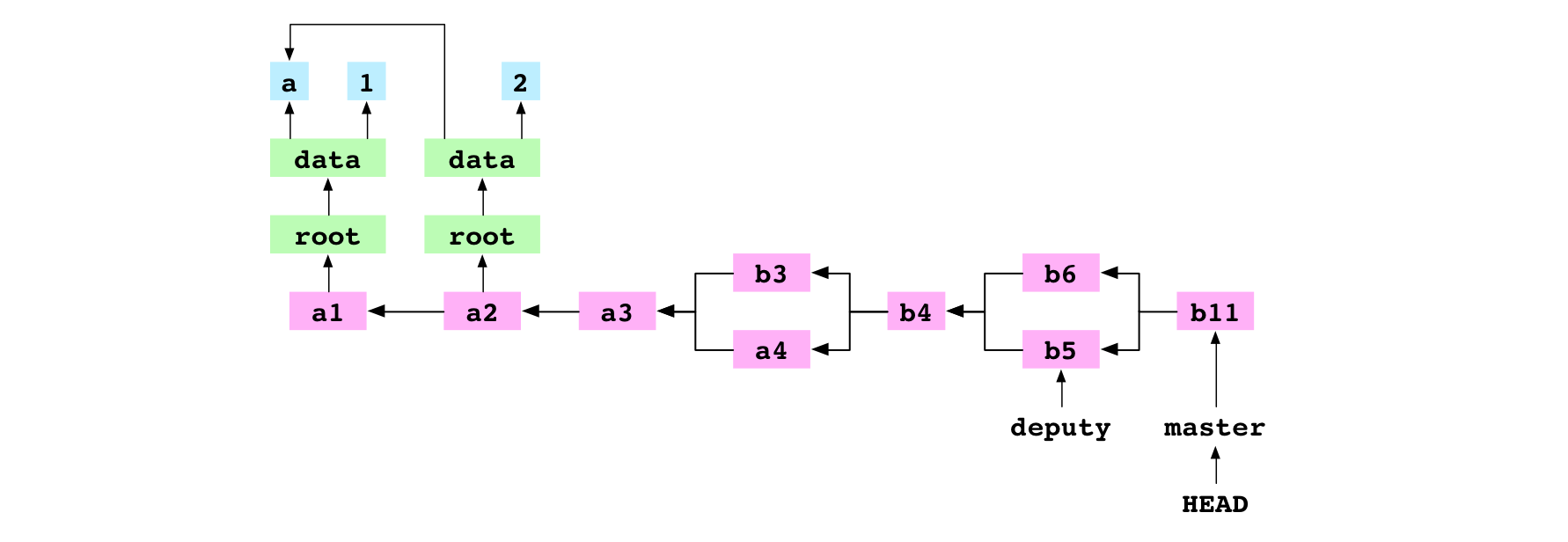
Remove a file
This diagram of the Git graph includes the commit history, the trees and blobs for the latest commit, and the working copy and index:
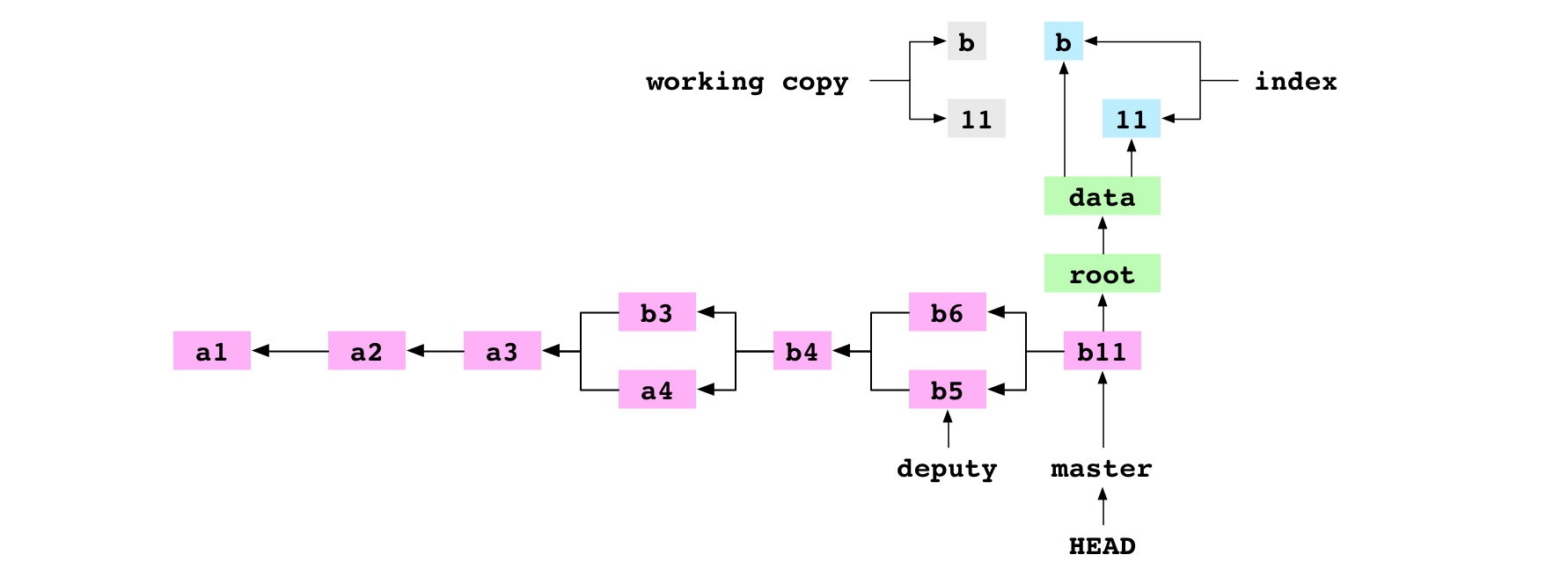
~/alpha $ git rm data/letter.txt
rm 'data/letter.txt'
The user tells Git to remove data/letter.txt. The file is deleted from the working copy. The entry is deleted from the index.
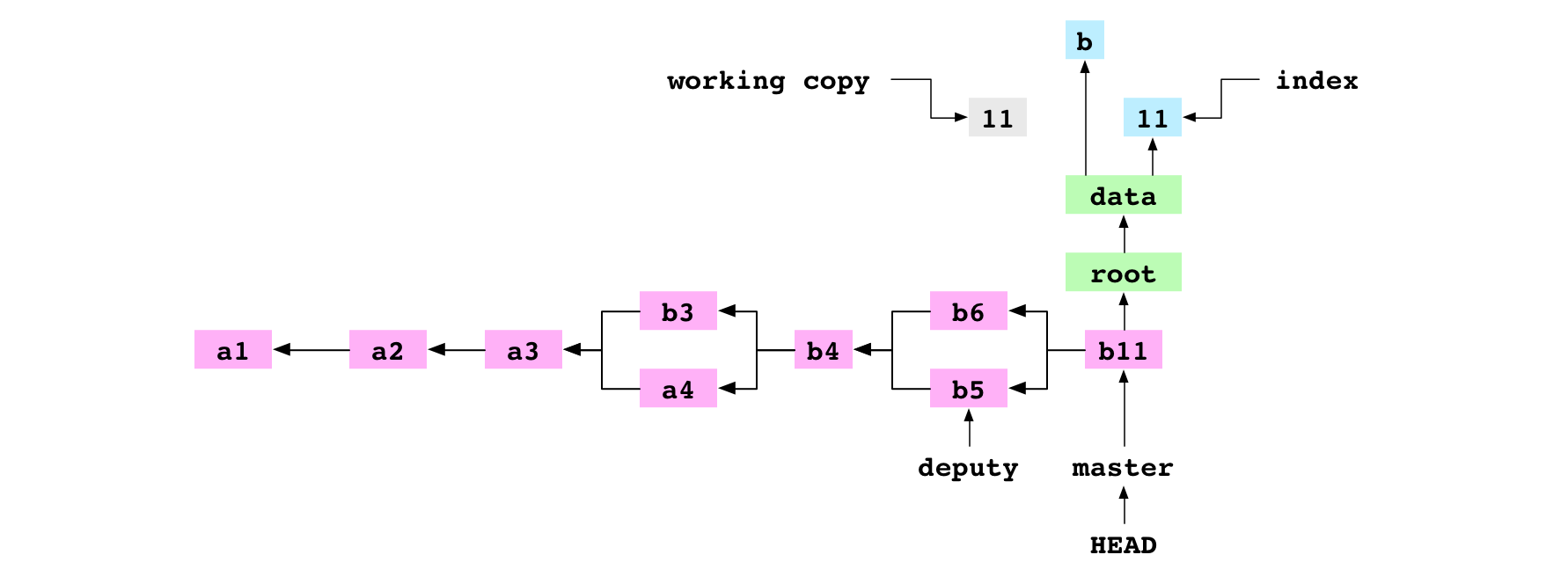
~/alpha $ git commit -m '11'
[master d14c7d2] 11
The user commits. As part of the commit, as always, Git builds a tree graph that represents the content of the index. data/letter.txt is not included in the tree graph because it is not in the index.
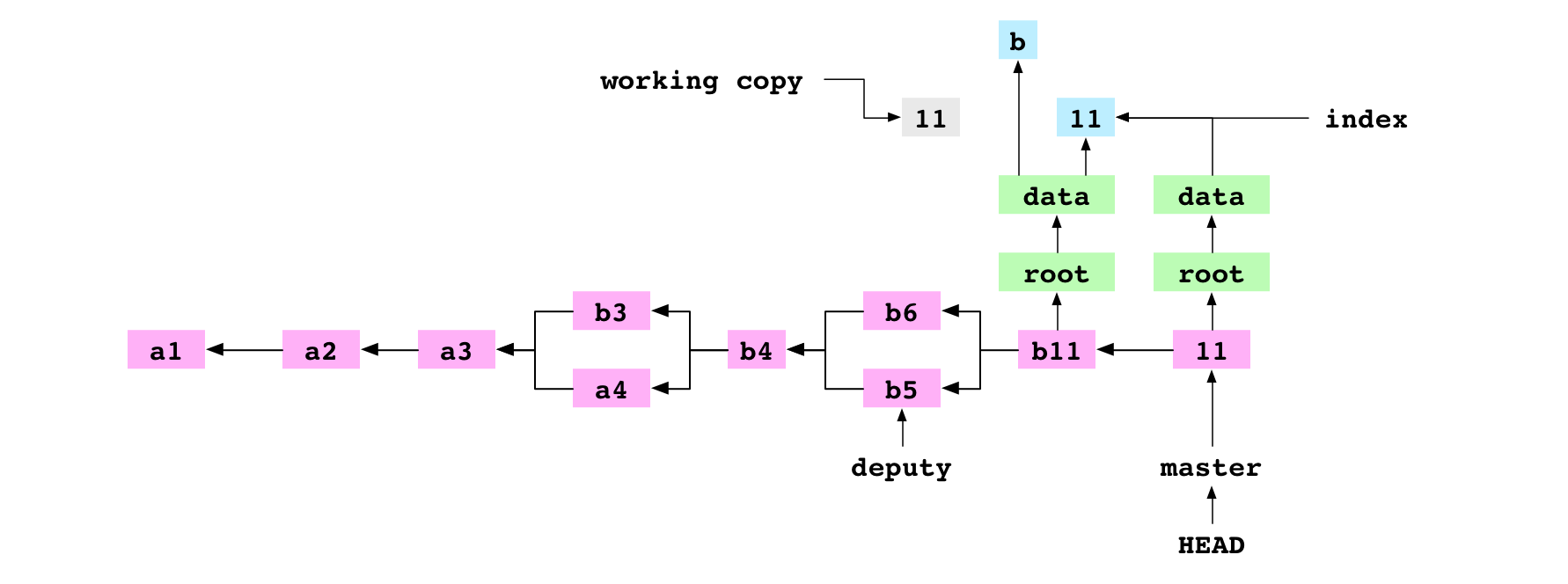
Copy a repository
~/alpha $ cd ..
~ $ cp -R alpha bravo
The user copies the contents of the alpha/ repository to the bravo/ directory. This produces the following directory structure:
~
├── alpha
| └── data
| └── number.txt
└── bravo
└── data
└── number.txt
There is now another Git graph in the bravo directory:
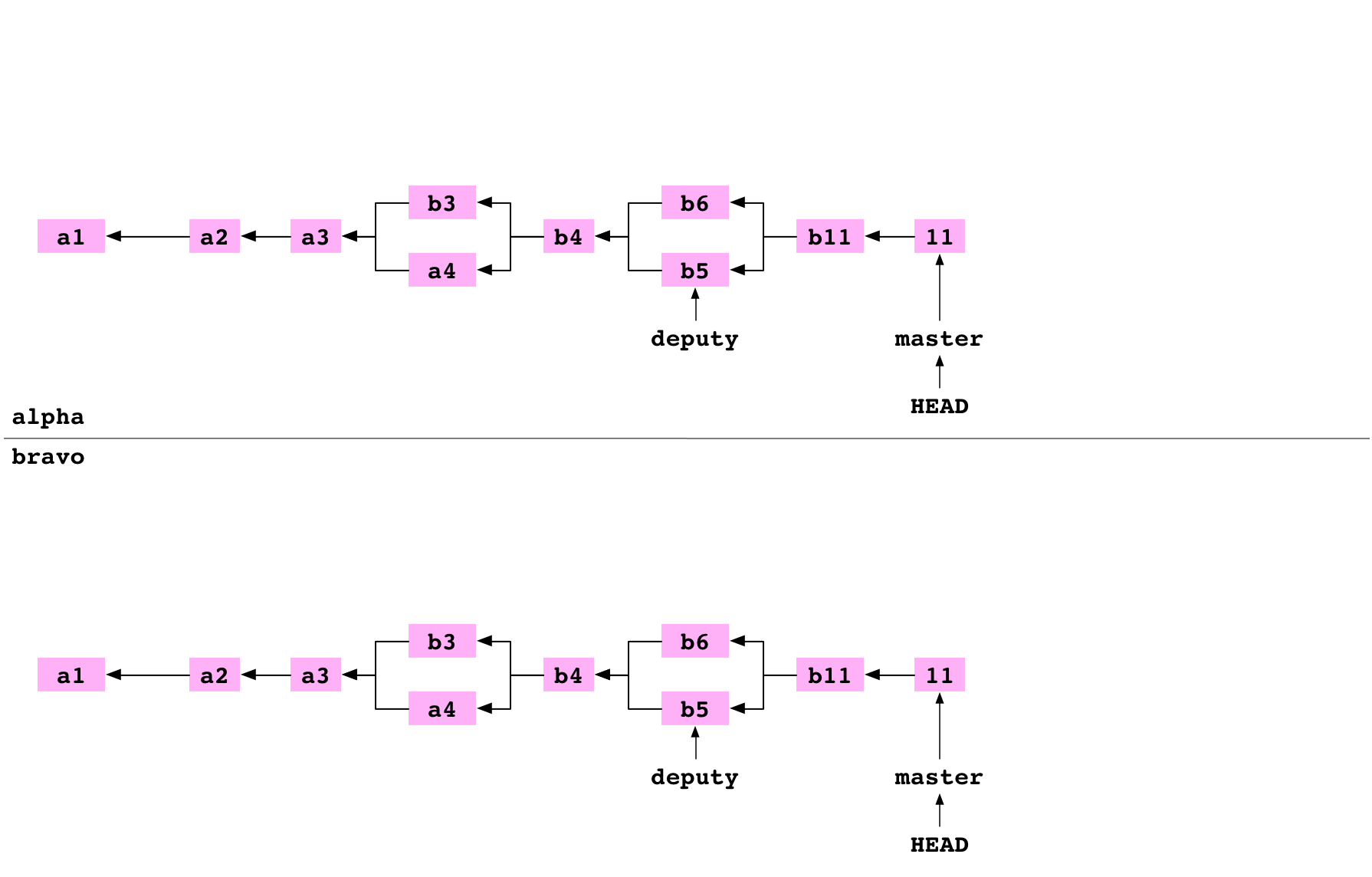
Link a repository to another repository
~ $ cd alpha
~/alpha $ git remote add bravo ../bravo
The user moves back into the alpha repository. They set up bravo as a remote repository on alpha. This adds some lines to the file at alpha/.git/config:
[remote "bravo"]
url = ../bravo/
These lines specify that there is a remote repository called bravo in the directory at ../bravo.
Fetch a branch from a remote
~/alpha $ cd ../bravo
~/bravo $ printf '12' > data/number.txt
~/bravo $ git add data/number.txt
~/bravo $ git commit -m '12'
[master 94cd04d] 12
The user goes into the bravo repository. They set the content of data/number.txt to 12 and commit the change to master on bravo.
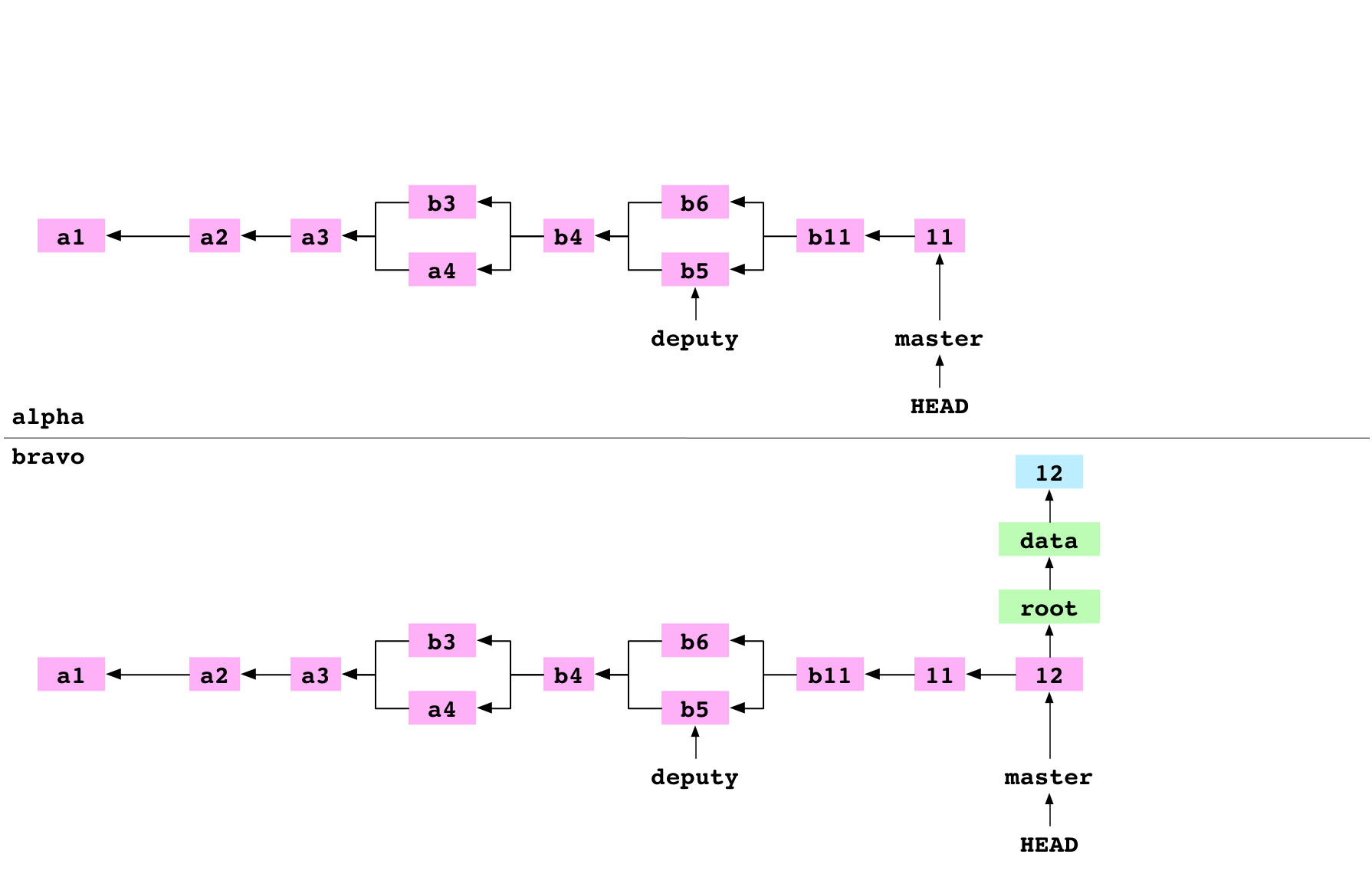
~/bravo $ cd ../alpha
~/alpha $ git fetch bravo master
Unpacking objects: 100%
From ../bravo
* branch master -> FETCH_HEAD
The user goes into the alpha repository. They fetch master from bravo into alpha. This process has four steps.
First, Git gets the hash of the commit that master is pointing at on bravo. This is the hash of the 12 commit.
Second, Git makes a list of all the objects that the 12 commit depends on: the commit object itself, the objects in its tree graph, the ancestor commits of the 12 commit and the objects in their tree graphs. It removes from this list any objects that the alpha object database already has. It copies the rest to alpha/.git/objects/.
Third, the content of the concrete ref file at alpha/.git/refs/remotes/bravo/master is set to the hash of the 12 commit.
Fourth, the content of alpha/.git/FETCH_HEAD is set to:
94cd04d93ae88a1f53a4646532b1e8cdfbc0977f branch 'master' of ../bravo
This indicates that the most recent fetch command fetched the 12 commit of master from bravo.
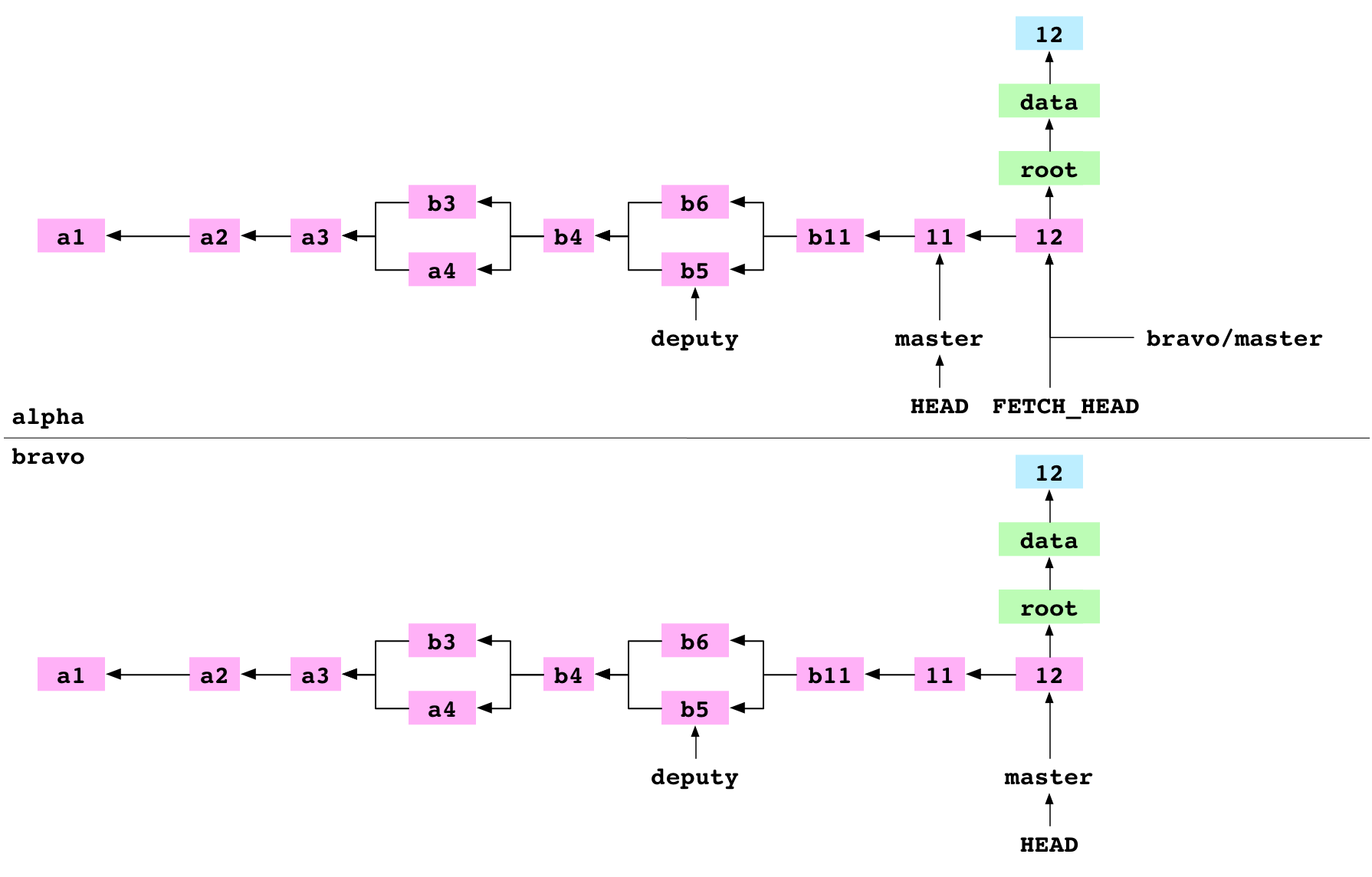
Graph property: objects can be copied. This means that history can be shared between repositories.
Graph property: a repository can store remote branch refs like alpha/.git/refs/remotes/bravo/master. This means that a repository can record locally the state of a branch on a remote repository. It is correct at the time it is fetched but will go out of date if the remote branch changes.
Merge FETCH_HEAD
~/alpha $ git merge FETCH_HEAD
Updating d14c7d2..94cd04d
Fast-forward
The user merges FETCH_HEAD. FETCH_HEAD is just another ref. It resolves to the 12 commit, the giver. HEAD points at the 11 commit, the receiver. Git does a fast-forward merge and points master at the 12 commit.
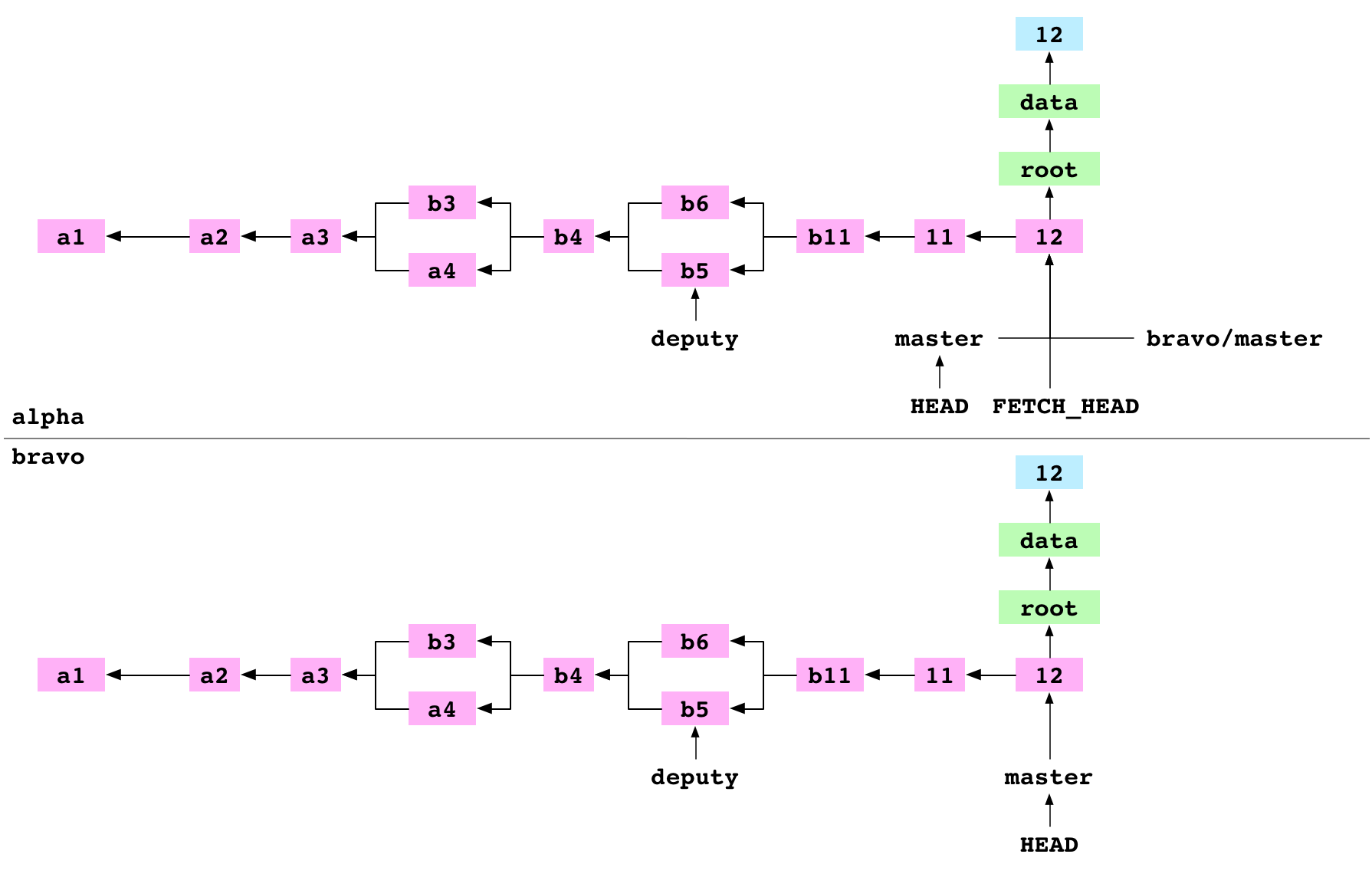
Pull a branch from a remote
~/alpha $ git pull bravo master
Already up-to-date.
The user pulls master from bravo into alpha. Pull is shorthand for “fetch and merge FETCH_HEAD”. Git does these two commands and reports that master is Already up-to-date.
Clone a repository
~/alpha $ cd ..
~ $ git clone alpha charlie
Cloning into 'charlie'
The user moves into the directory above. They clone alpha to charlie. Cloning to charlie has similar results to the cp the user did to produce the bravo repository. Git creates a new directory called charlie. It inits charlie as a Git repo, adds alpha as a remote called origin, fetches origin and merges FETCH_HEAD.
Push a branch to a checked-out branch on a remote
~ $ cd alpha
~/alpha $ printf '13' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m '13'
[master 3238468] 13
The user goes back into the alpha repository. They set the content of data/number.txt to 13 and commit the change to master on alpha.
~/alpha $ git remote add charlie ../charlie
They set up charlie as a remote repository on alpha.
~/alpha $ git push charlie master
Writing objects: 100%
remote error: refusing to update checked out
branch: refs/heads/master because it will make
the index and work tree inconsistent
They push master to charlie.
All the objects required for the 13 commit are copied to charlie.
At this point, the push process stops. Git, as ever, tells the user what went wrong. It refuses to push to a branch that is checked out on the remote. This makes sense. A push would update the remote index and HEAD. This would cause confusion if someone were editing the working copy on the remote.
At this point, the user could make a new branch, merge the 13 commit into it and push that branch to charlie. But, really, they want a repository that they can push to whenever they want. They want a central repository that they can push to and pull from, but that no one commits to directly. They want something like a GitHub remote. They want a bare repository.
Clone a bare repository
~/alpha $ cd ..
~ $ git clone alpha delta --bare
Cloning into bare repository 'delta'
The user moves into the directory above. They clone delta as a bare repository. This is an ordinary clone with two differences. The config file indicates that the repository is bare. And the files that are normally stored in the .git directory are stored in the root of the repository:
delta
├── HEAD
├── config
├── objects
└── refs
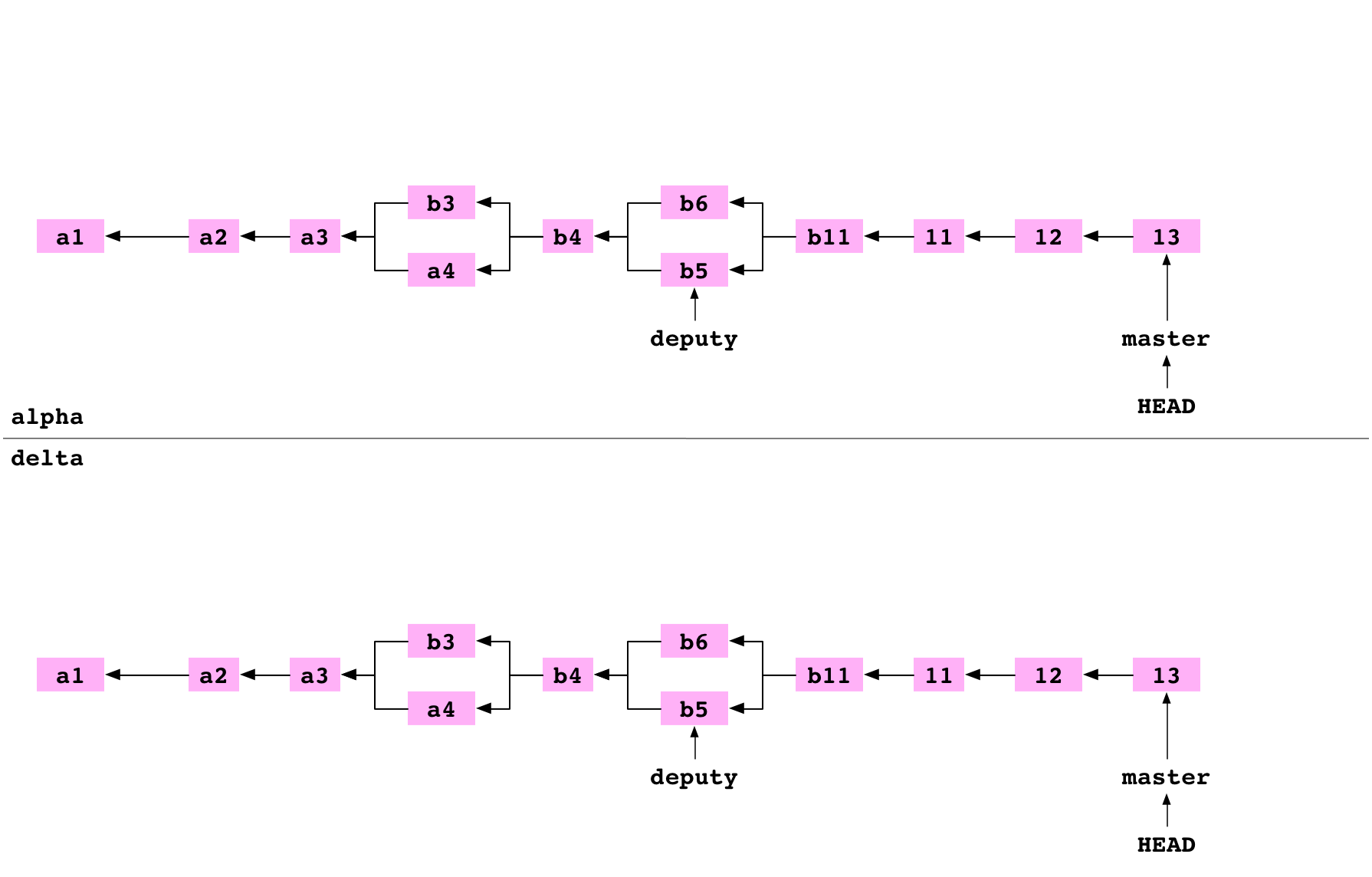
Push a branch to a bare repository
~ $ cd alpha
~/alpha $ git remote add delta ../delta
The user goes back into the alpha repository. They set up delta as a remote repository on alpha.
~/alpha $ printf '14' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m '14'
[master cb51da8] 14
They set the content of data/number.txt to 14 and commit the change to master on alpha.
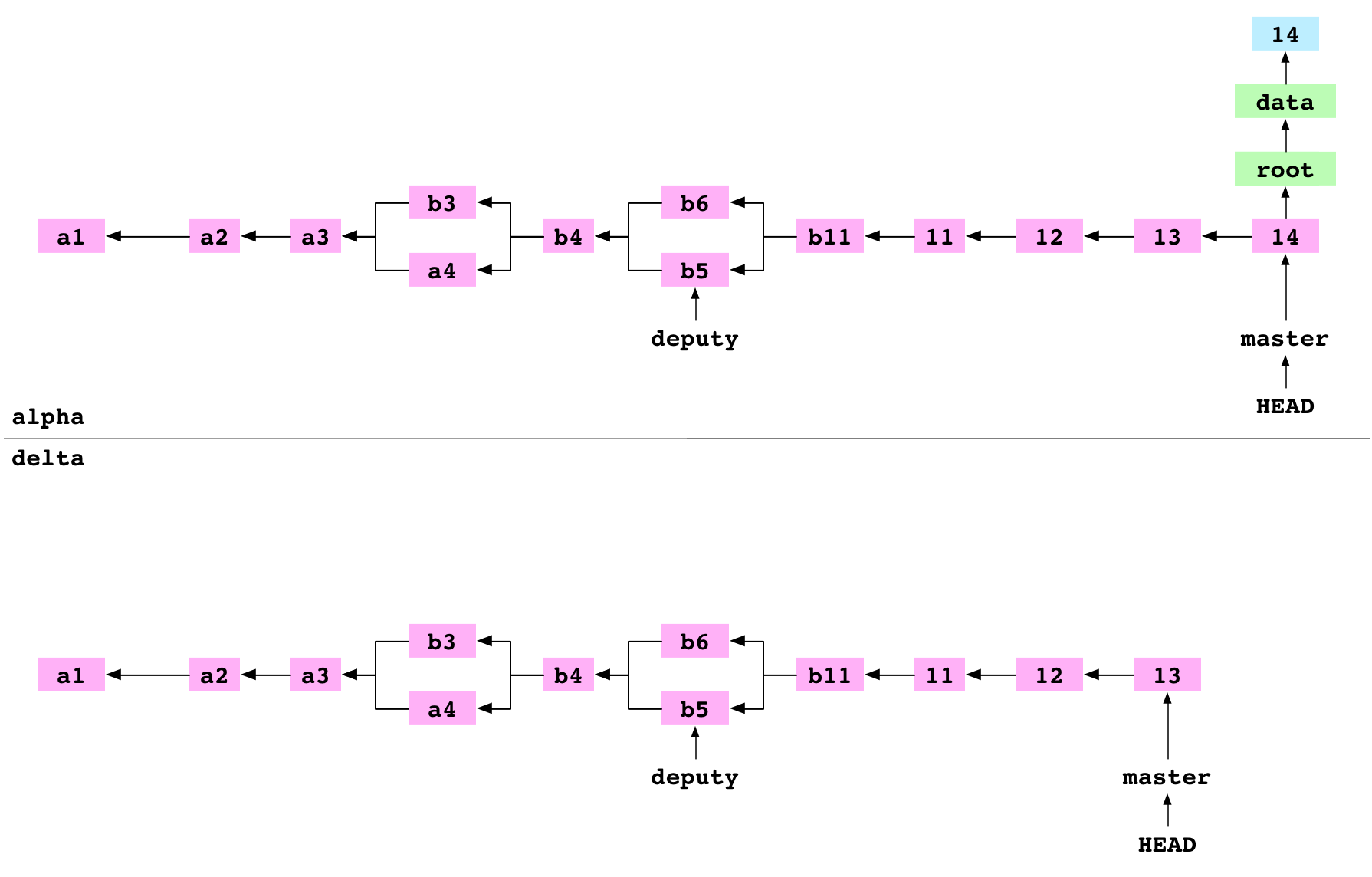
~/alpha $ git push delta master
Writing objects: 100%
To ../delta
3238468..cb51da8 master -> master
They push master to delta. Pushing has three steps.
First, all the objects required for the 14 commit on the master branch are copied from alpha/.git/objects/ to delta/objects/.
Second, delta/refs/heads/master is updated to point at the 14 commit.
Third, alpha/.git/refs/remotes/delta/master is set to point at the 14 commit. alpha has an up-to-date record of the state of delta.
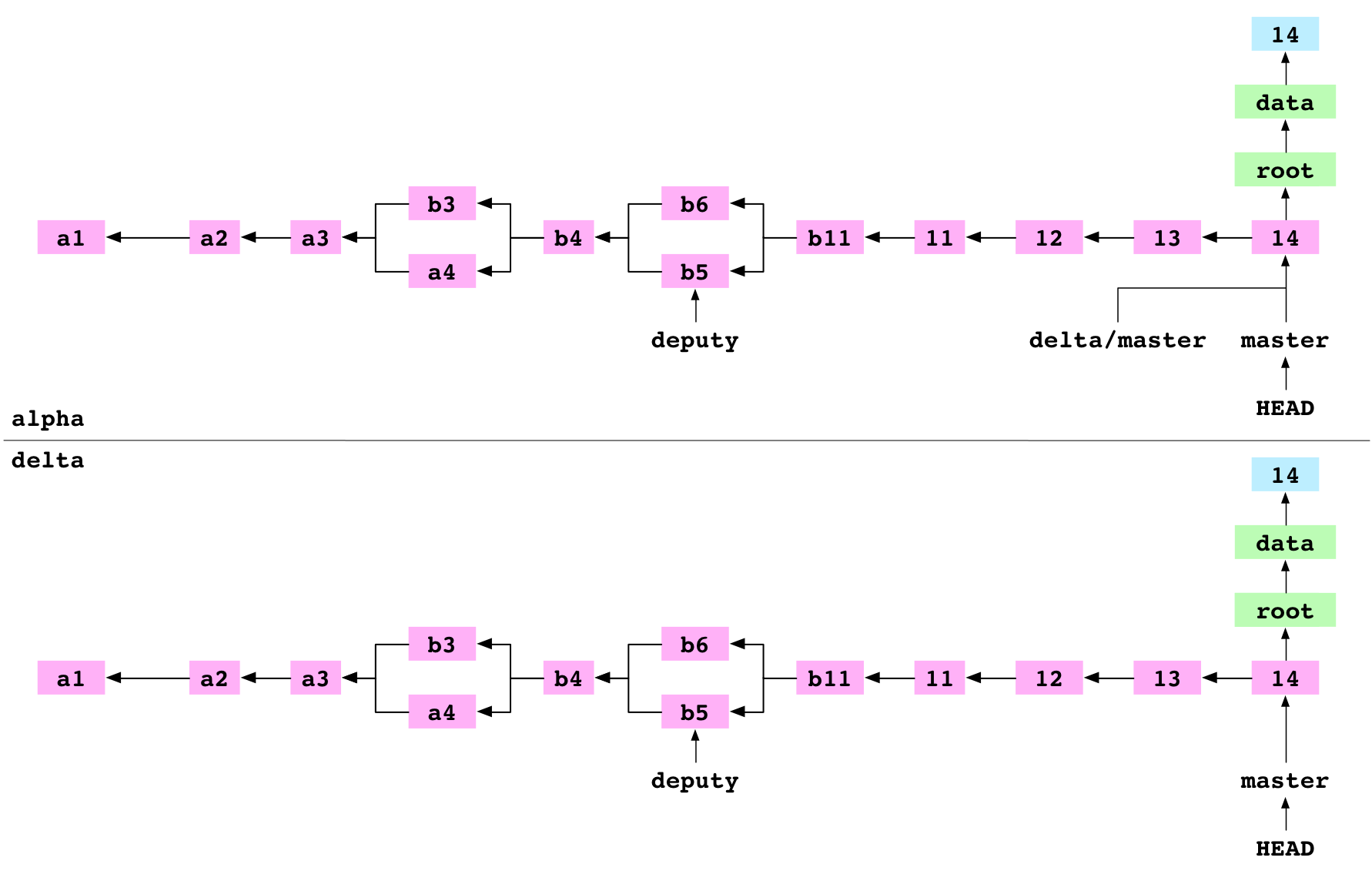
Summary
Git is built on a graph. Almost every Git command manipulates this graph. To understand Git deeply, focus on the properties of this graph, not workflows or commands.
To learn more about Git, investigate the .git directory. It’s not scary. Look inside. Change the content of files and see what happens. Create a commit by hand. Try and see how badly you can mess up a repo. Then repair it.
-
In this case, the hash is longer than the original content. But, all pieces of content longer than the number of characters in a hash will be expressed more concisely than the original. ↩
-
There is a chance that two different pieces of content will hash to the same value. But this chance is low. ↩
-
git prunedeletes all objects that cannot be reached from a ref. If the user runs this command, they may lose content. ↩ -
git stashstores all the differences between the working copy and theHEADcommit in a safe place. They can be retrieved later. ↩ -
The
rebasecommand can be used to add, edit and delete commits in the history. ↩
Introducing Gitlet
For the last few months, I have been writing Gitlet, an implementation of Git in JavaScript. This post is about the code and what it was like to write it.
I had two goals with Gitlet.
First, I wanted to learn the innards of Git really well.
Second, I wanted to use that knowledge to produce an essay, Git from the inside out, that gives a clear, deep explanation of Git and the ideas underlying it.
My implementation of Git is not intended to be fast or feature-complete. It is intended to support commands that are commonly used and that demonstrate the core ideas in Git: init, add, rm, commit, branch, checkout, diff, remote, fetch, merge, push, pull, status and clone. For example, I implemented remote, but only supported git remote add because git remote remove and the rest are just conveniences and their implementation says nothing about the essence of Git.
For another example, I implemented merge and supported fast forwards, un-conflicting merges and conflicted merges. But, for conflicted files, the whole file is written as conflicting, rather than just the incompatible sections. The difference between fast forwards and merge commits gets to the heart of Git. Figuring out which sections of a file have changed does not.
I wrote the code to be short and very easy to understand. I eagerly welcome pull requests that make the code shorter or easier to understand. And, of course, bug fixes are much appreciated.
It’s hard to say how much you need to know about Git to understand the code. If you don’t know much about the inner logic of Git, it is probably worth it to first read my essay, Git in six hundred words. But, if you already know what blobs and trees and fast forwards are, the code should be interesting. Though the entire project is 1000 lines, the implementation of the main API commands is only 350 lines.
Finally, I want to talk about what it was like to write the code.
First, it was hard to figure out how Git works. I went to the actual source to answer a few questions. But doing that was time-consuming because I don’t know C well. A Hacker’s Guide to Git was a killer introduction to the internals of Git. It gave me a grounding in most of the commands I implemented. Stack Overflow was helpful on some obscure questions. I read a lot of Git documentation. I referred again and again to this elegant, detailed Quora answer on how merging works. I didn’t implement recursive merges in the end, but this great Codice Software post helped me understand them. But, mostly, I could only answer my questions by creating repositories and running commands and diving into the .git directory to see what had happened.
Second, I had a strange feeling of discovery. This feeling is hard to talk about. Some behaviours were inexplicably difficult to implement. I’d write ten lines that felt like they should be two. But, slowly, patterns began to emerge. I found that particular shapes of data occurred again and again. I could represent directory hierarchies with nested objects. I could represent indices by mapping file paths to hashes. I could represent diffs by mapping paths to a change status and the hashes of the old, new and base versions. Once I had code to create and translate these data structures, the Git API became much easier to implement.
And I found that fundamental operations on the .git directory could be composed to implement Git API commands. For example: implementing checkout. Read the current HEAD, get the commit hash it points at, read the commit object, read the commit tree content and convert the content to an index. Repeat for the branch to be checked out. Diff the two indices. Write that diff to the working copy. Write the name of the branch being checked out to HEAD. Convert the commit being checked out to an index. Write that index to the index file.
These basic data types and operations seemed to express something of the fundamental nature of Git. I’ve had this feeling before when working on novel projects. But it was funny to feel the sensation of discovery when working on something that already existed.
Git in six hundred words
(This essay is a companion piece to Gitlet, my implementation of Git in JavaScript.)
Imagine you have a directory called alpha. It contains a file called number.txt that contains the text first.
You run git init to set up alpha as a Git repository.
You run git add number.txt to add number.txt to the index. The index is a list of all the files that Git is keeping track of. It maps filenames to the content of the files. It now has the mapping number.txt -> first. Running the add command has also added a blob object containing first to the Git object database.
You run git commit -m first. This does three things. First, it creates a tree object in the objects database. This object represents the list of items in the top level of the alpha directory. This object has a pointer to the first blob object that was created when you ran git add. Second, it creates a commit object that represents the version of the repository that you have just committed. This includes a pointer to the tree object. Third, it points the master branch at the new commit object.
You run git clone . ../beta. This creates a new directory called beta. It initializes it as a Git repository. It copies the objects in the alpha objects database to the beta objects database. It points the master branch on beta at the commit object that the master branch points at on the alpha repository. It sets the index on beta to mirror the content of the first commit. It updates your files - number.txt - to mirror the index.
You move to the beta repository. You change the content of number.txt to second. You run git add number.txt and git commit -m second. The commit object that is created has a pointer to its parent, the first commit. The commit command points the master branch at the second commit.
You move back to the alpha repository. You run git remote add beta ../beta. This sets the beta repository as a remote repository.
You run git pull beta master.
Under the covers, this runs git fetch beta master. This finds the objects for the second commit and copies them from the beta repository to the alpha repository. It points alpha’s record of beta’s master at the second commit object. It updates FETCH_HEAD to show that the master branch was fetched from the beta repository.
Under the covers, the pull command runs git merge FETCH_HEAD. This reads FETCH_HEAD, which shows that the master branch on the beta repository was the most recently fetched branch. It gets the commit object that alpha’s record of beta’s master is pointing at. This is the second commit. The master branch on alpha is pointing at the first commit, which is the ancestor of the second commit. This means that, to complete the merge, the merge command can just point the master branch at the second commit. The merge command updates the index to mirror the contents of the second commit. It updates the working copy to mirror the index.
You run git branch red. This creates a branch called red that points at the second commit object.
You run git checkout red. Before the checkout, HEAD pointed at the master branch. It now points at the red branch. This makes the red branch the current branch.
You set the content of number.txt to third, run git add numbers.txt and run git commit -m third.
You run git push beta red. This finds the objects for the third commit and copies them from the alpha repository to the beta repository. It points the red branch on the beta repository at the third commit object, and that’s it.
(If you would like to learn about the internals of Git in detail, you can read my essay, Git from the inside out.)
Racecar
In December 2014, I did the Ludum Dare game jam. I made Racecar, a top-down 2D racing game, in forty-eight hours. I used Coquette, my micro framework for JavaScript games. A few days later, I cleaned up the Racecar code and added the game to the Coquette demos.
My speech to new Recursers
Hi. I’m Mary. I’m a facilitator at the Recurse Center.
First, I’m going to talk about what facilitators do. Second, I’m going to give you advice about making the most of your time at the Recurse Center.
What do facilitators do?
We’re here to help you help yourselves learn. We can do that in a number of ways.
We can review your code. That is: we can look at your code and talk about ways it might be improved. If you want code review, it’s best if you come prepared. Identify areas of your code that you’re worried about. Or pick a part of your program and a goal, like making the code faster, more idiomatic, shorter, easier to read, more functional or more object-oriented.
We can pair program with you. That is: we can collaborate with you on your code. When you pair with someone, try and be your most conscientious programmer self. Practice higher level programming skills like diving deep and debugging systematically.
We can help you choose a project that fits your learning goals for the Recurse Center. This might mean pointing you for inspiration to the well-thumbed list of Fun and Educational Recurse Center Projects. This might mean talking through what your learning goals actually are.
We run workshops on subjects that interest us. Recently, I’ve run workshops on getting started with functional programming, writing a game and exploring prototypal inheritance in JavaScript.
We can give you advice on how to get started with a new project or technology. That might mean talking about a reasonable architecture for your project. Or it might mean talking through the basics of a technology.
We can recommend other Recursers, facilitators or alumni who share your interests and who you might enjoy working with.
We can help you get unstuck when you’ve been struggling with a problem. Some of us use a guideline about when to ask for help. If you’re stuck, you must struggle for fifteen minutes. If you’ve struggled for fifteen minutes, you must ask for help. One useful way to spend that fifteen minutes is to rubber duck your problem. That is, explain your problem out loud or in your head to a literal or notional yellow rubber duck. Sometimes, this yields the answer. Sometimes, it identifies a promising avenue of investigation. And it always clarifies your understanding of the problem.
Finally, we can talk to you if you’re having problems in your personal life. Your time at the Recurse Center can be hard. It’s a new environment that is isolated from family and old friends. We can talk with you about problems you’re having.
All the things facilitators do for you can be done by you for each other: code review, pairing, running workshops, giving counsel and so on. There’s only one difference between facilitators and Recursers. Your priority is your learning. But we’re paid to be here, so our priority is your learning, too.
Advice for getting the most out of your time at the Recurse Center
You’ve probably made big sacrifices to come here. Maybe you’ve saved up all your money for months or years. Maybe you’ve quit your job. Maybe you’ve moved to a new city. Maybe you’ve decided to neglect your hobbies, or your friends, or your children.
If you make your time at the Recurse Center the most productive three months of your life, that’s fine. That’s pretty OK. But, given the sacrifices you’ve made, it would be even better to use your time here to learn skills that will compound your improvement as a programmer forever. The Recurse Center is a great place to put into muscle memory these higher level skills that get neglected under pressure from grades or bosses or worrying about what the internet will think.
There are four skills that have paid great dividends for me.
Dive deep. You’re using a framework, library or language and you realise you don’t understand something about it. Take the time to understand by reading the source, playing around in a REPL or reading the documentation. This will cement your mental model and help make you a sure-footed programmer.
Debug systematically. When you’re stuck on a bug, don’t just type in things you think might fix the problem. Form a hypothesis about what the problem is, then run experiments. If the results support the hypothesis, the problem is now clear and that is most of the battle. Otherwise, use the observations from your experiments to form a new hypothesis.
Learn your tools. Fix those nagging problems in your config. Learn more keyboard shortcuts. Automate processes you do regularly. Don’t lose days on this. Fix one thing, then get back to work.
Learn one programming language really well. This takes months or years. But it has two big advantages. First, you now have a language you can think in. You can express an algorithm or a thought fluently without looking up syntax or APIs. Second, you will learn about the deep ideas in programming. You could learn these deep ideas by learning new languages. Programming in Erlang teaches you about concurrency. Programming in C teaches you about memory management. But sticking with one language keeps you in familiar surroundings. This lets you appreciate the subtleties of these fundamental ideas. You, know: space, time, shit like that.
Scarface, Prince of the City and Pieter de Hooch
Brian De Palma is very good at making his scenes feel like they are part of a living world. Look at the first drug deal in Scarface. There are two shots that connect the car on the street to the rooms in the apartment where the deal is being done.
In the first shot, the camera follows Tony and Chico across the road and up the stairs to the door of the apartment.
In the second shot, the camera goes from the window of the sitting room, down into the street to the car, then back up into the apartment through the bathroom window.
But, the effect of a living world is diluted by a feeling of voyeurism. The second shot relies on the movement of the camera, rather than the movement of the objects in the scene. The camera is independent of the world.
Sidney Lumet achieves the same effect of a living world. But, his camera is mostly an observer. It is static, or it makes only unintrusive movements. It never peers. In this shot from Prince of the City, a whole block is brought alive when two running men disappear behind a building and reappear on the other side. The pan and track show us the action, but at a remove. Like the first Scarface shot, it is the movement of the characters from one place to another that brings everything to life. But, Lumet creates an even subtler effect by making the men disappear and reappear. This goes beyond connecting one visible place to another. It suggests places that are out of sight, which is more evocative of a living world.
Pieter de Hooch achieves the same effect in his painting, Paying the Hostess. Look at how light in the sky on the far left shines in through a hidden window, through a mostly obscured back room and finally falls on the wall on the far right. The light makes real the things we can’t see. It, too, is better than de Palma because it achieves its effect by making something disappear and then reappear. But, remarkably, de Hooch does it with a still image. No moving objects. No moving frame. Just moving light.

Testing from the ground up
Tests are pieces of code that check if your main code works. I write tests to catch bugs when I refactor. I write tests to force myself to think through and handle edge cases. I write tests to show the users of my project that my code does what I say it does.
For this essay, I will describe the code and tests for a tiny web app that draws a blue sky if it’s day time.

And a black sky if it’s night time.

I will describe all the code I wrote. The web app. The microscopic testing framework. The tests for the client side code. The mocks that fake layers of the web app and technologies that are not pertinent. The tests that use these mocks. The refactored code that simplifies the mocks by dividing the web app code into different pieces that have single responsibilites.
Along the way, I will talk about many fun things. Temporarily patching libraries written by other people. Writing code that pretends to be the internet. Making Ajax requests by hand. Writing a little web server. Examining a function to find out how many arguments it expects. Making asynchronous blocks of code run serially so they don’t tread on each other’s toes.
The code
To see the code from this essay in runnable form, go to the Testing From The Ground Up GitHub repository. At each evolution of the code, I will include a link to the corresponding commit.
The web app
This is the HTML that defines the only page in the web app. It has a canvas element that displays the sky. It loads the client side JavaScript, client.js. When the DOM is ready, it calls loadTime(), the one and only function.
<!doctype html>
<html>
<head>
<script src="client.js"></script>
</head>
<body onload="loadTime();">
<canvas id="canvas" width="600" height="100"></canvas>
</body>
</html>
Below is the client side JavaScript.
loadTime() starts by making an Ajax request to the server to get the current time. This is done in several steps. First, it creates an XMLHttpRequest object. Second, near the bottom of the function, it configures the object to make a GET request to "/time.json". Third, it sends the request. Fourth, when the requested time data arrives at the client, the function bound to request.onload fires.
The bound function grabs the drawing context for the canvas element. It parses "day" or "night" from the JSON returned by the server. If the value is "day", it sets the draw color to blue and draws a rectangle that takes up the whole canvas. If the value is "night", the color is black.
;(function(exports) {
exports.loadTime = function() {
var request = new XMLHttpRequest();
request.onload = function(data) {
var ctx = document.getElementById("canvas").getContext("2d");
var time = JSON.parse(data.target.responseText).time;
var skyColor = time === "day" ? "blue" : "black";
ctx.fillStyle = skyColor;
ctx.fillRect(0, 0, ctx.canvas.width, ctx.canvas.height);
};
request.open("GET", "/time.json", true);
request.send();
};
})(this);
Below is the server-side JavaScript. It is run in Node.js. Near the bottom, the code uses the Node HTTP module to create a web server. It specfies that every web request should be handled by requestHandler(). Each time this function is called, Node passes it a request object that has the URL that was requested, and a response object that can be used to send data back to the client.
If the client requested "/", the root, the index.html file is read from disk and its contents are sent back to be displayed in the user’s browser. If "/time.json" was requested, the server looks up the time, creates a piece of JSON that looks something like { "time": "day" } and sends it back to the user’s web browser.
var http = require("http");
var fs = require("fs");
var requestHandler = function (request, response) {
if (request.url === "/") {
fs.readFile(__dirname + "/index.html", function (err, data) {
response.writeHead(200, { "Content-Type": "text/html" });
response.end(data);
});
} else if (request.url === "/client.js") {
fs.readFile(__dirname + "/client.js", function (err, data) {
response.writeHead(200, { "Content-Type": "application/javascript" });
response.end(data);
});
} else if (request.url === "/time.json") {
response.writeHead(200, { "Content-Type": "application/json" });
var hour = new Date().getHours();
var time = hour > 6 && hour < 20 ? "day" : "night";
response.end('{ "time": "' + time + '" }');
}
};
http.createServer(requestHandler).listen(4000);
exports.requestHandler = requestHandler;
Here is the code for the basic web app.
A miniscule testing framework
It is possible to write tests that each include the generic code for reporting their outcome, for reporting errors, for calling the next test. But, that means a lot of repetition. It’s easier to use a testing framework. This is the one I wrote.
var test = function() {
gatherTests(arguments).forEach(function(userTest) {
userTest();
process.stdout.write(".");
});
console.log();
};
test.isEqual = function(a, b) {
if (a !== b) {
throw a + " and " + b + " are not equal";
}
};
var gatherTests = function(testArgs) {
return Array.prototype.slice.call(testArgs).filter(function(x, i) {
return i % 2 === 1;
});
};
module.exports = test;
test() could be used to write a test like this:
var test = require("./test");
test(
"should test 1 equals 1", function() {
test.isEqual(1, 1);
});
Which, when run, would look like this:
$ node test.js
.
How does the testing framework run the tests it is given?
test() takes a series of arguments that alternate between string descriptions and test functions. It throws away the ones that are strings, which are merely human-readable window-dressing. It puts the functions into an array. It walks through that array, calling each function and printing a period to indicate that the test passed.
The test functions use test.isEqual() to assert that certain variables have certain values. (A real testing framework would have a more permissive and pragmatic version of isEqual() that returned true in a case like test.isEqual({ love: "you" }, { love: "you" }).) If an assertion turns out to be unfounded, an exception is thrown, an error is printed and the tests stop running.
Mocking the server and the internet
I don’t want to have to run the server when I run the tests. That would be an extra step. It would add statefulness that would need to be reset before each test. It would necessitate network communications between the test and the server.
This is the code I wrote that pretends to be the server deciding what time it is and the internet relaying that information back to the client. It does this by faking an Ajax request. It replaces the XMLHttpRequest constructor function with a function that returns a home-made Ajax request object. This object swallows the web app’s call to open(). When the web app calls send(), it calls the function that the web app has bound to onload. It passes some fake JSON that makes it seem like it is always day time.
global.XMLHttpRequest = function() {
this.open = function() {};
this.send = function() {
this.onload({
target: { responseText: '{ "time": "day" }' }
});
};
};
Mocking the canvas and the DOM
When the real code runs in a real web browser, it renders the sky to the real canvas in real blue. This is problematic. First, I don’t want to require a browser to test my code. Second, even if I capitulated to that requirement, it would be hard to check if the right thing happened. I would probably need to look at the individual pixels of the canvas drawing context to see if they were bluey.
Instead of walking down that horrid road, I wrote some code that pretends to be the browser DOM and the canvas element. It redefines getElementById() to return a fake canvas. This has a fake getContext() that returns a fake drawing context that has a fake fillRect() and a fake reference to a fake canvas that has a width and height. Instead of drawing, this function checks that the arguments passed to it have the expected values.
global.document = {
getElementById: function() {
return {
getContext: function() {
return {
canvas: { width: 300, height: 150 },
fillRect: function(x, y, w, h) {
test.isEqual(x, 0);
test.isEqual(y, 0);
test.isEqual(w, 300);
test.isEqual(h, 150);
test.isEqual(this.fillStyle, "blue");
}
};
}
};
}
};
This is the full test.
var test = require("./test");
var client = require("../client");
test(
"should draw blue sky when it is daytime", function() {
global.XMLHttpRequest = function() {
this.open = function() {};
this.send = function() {
this.onload({
target: { responseText: '{ "time": "day" }' }
});
};
};
global.document = {
getElementById: function() {
return {
getContext: function() {
return {
canvas: { width: 300, height: 150 },
fillRect: function(x, y, w, h) {
test.isEqual(x, 0);
test.isEqual(y, 0);
test.isEqual(w, 300);
test.isEqual(h, 150);
test.isEqual(this.fillStyle, "blue");
}
};
}
};
}
};
client.loadTime();
});
Don’t worry. That code is as bad as this essay gets.
Here is the code that includes the testing framework and the first client side test.
The drawing code refactored into its own module
Those mocks are pretty horrid. They make the test very long, which discourages me from writing tests to check for other ways the code might go wrong. The mocks are horrid because the client side code is one big function that communicates with the server, asks what time it is, parses the response and draws in the canvas.
To solve this problem, I refactored the code by pulling the drawing code out into its own module, renderer. This module includes fillBackground(), a function that fills the canvas with the passed color. As a side benefit, the main web app code is now easier to understand and change.
;(function(exports) {
exports.loadTime = function() {
var request = new XMLHttpRequest();
request.onload = function(data) {
var time = JSON.parse(data.target.responseText).time;
var color = time === "day" ? "blue" : "black";
renderer.fillBackground(color);
};
request.open("GET", "/time.json", true);
request.send();
};
var renderer = exports.renderer = {
ctx: function() {
return document.getElementById("canvas").getContext("2d");
},
fillBackground: function(color) {
var ctx = this.ctx();
ctx.fillStyle = color;
ctx.fillRect(0, 0, ctx.canvas.width, ctx.canvas.height);
}
};
})(this);
This lets me replace the complex document mock with a short renderer.ctx() mock. The test becomes shorter, simpler and less brittle.
var test = require("./test");
var client = require("../client");
test(
"should draw sun and blue sky in canvas when it is daytime", function() {
global.XMLHttpRequest = function() {
this.open = function() {};
this.send = function() {
this.onload({
target: { responseText: '{ "time": "day" }' }
});
};
};
client.renderer.ctx = function() {
return {
canvas: { width: 300, height: 150 },
fillRect: function(x, y, w, h) {
test.isEqual(x, 0);
test.isEqual(y, 0);
test.isEqual(w, 300);
test.isEqual(h, 150);
test.isEqual(this.fillStyle, "blue");
}
}
};
client.loadTime();
});
Here is the code for the modularised renderer and resulting simplified client side test.
I modularised the client side code further by splitting out three more functions.
This is get(). It makes an Ajax request to the passed URL. The Ajax request object calls the passed callback with the response.
var get = exports.get = function(url, callback) {
var request = new XMLHttpRequest();
request.onload = callback;
request.open("GET", url, true);
request.send();
};
This is getTime(). It uses get() to make an Ajax request to "/time.json" and parses "day" or "night" from the response.
exports.getTime = function(callback) {
exports.get("/time.json", function(data) {
callback(JSON.parse(data.target.responseText).time);
});
};
This is displayTime(). It takes a string with the value "day" or "night" and draws either a blue sky or a black sky.
exports.displayTime = function(time) {
var color = time === "day" ? "blue" : "black";
renderer.fillBackground(color);
};
I changed the body tag in the HTML page. It now calls getTime(), passing displayTime() as the callback.
<body onload="getTime(displayTime);">
<canvas id="canvas" width="600" height="100"></canvas>
</body>
Having more modular code means that I can mock parts of the web app API, rather than mocking code written by third parties. This makes it easier to write tests that test a specific piece of functionality.
Using this refactor, I could write tests that are more extensive. The first test checks that getTime() correctly parses JSON sent by the server. The second test checks that a call to fillBackground() draws a rectangle at the correct position and size. The third test checks that displayTime() draws a rectangle of the correct color for the time of day.
var test = require("./test");
var client = require("../client");
test(
"should parse time from server", function() {
client.get = function(_, callback) {
callback({ target: { responseText: '{ "time": "day" }' }});
};
client.getTime(function(time) { test.isEqual(time, "day"); });
},
"should draw rect of passed size and color when fillBackground() called", function() {
client.renderer.ctx = function() {
return {
canvas: { width: 300, height: 150 },
fillRect: function(x, y, w, h) {
test.isEqual(x, 0);
test.isEqual(y, 0);
test.isEqual(w, 300);
test.isEqual(h, 150);
}
}
};
client.renderer.fillBackground("blue");
},
"should draw blue sky when it is daytime", function() {
client.renderer.fillBackground = function(color) {
test.isEqual(color, "blue");
};
client.displayTime("day");
});
Here is the code for the more modular client code and more extensive tests.
Testing the server side code
Asynchronous tests
Some of the responsibilities of a web server require asynchronous operations. If a browser sends a request to the web app for the URL "/", it gets back the contents of the index.html file. To make this happen, the file needs to be read from disk asynchronously and the contents sent to the client once they have been read. Similarly, if the browser requests the URL "/client.js", it gets back the contents of the client.js file.
These are the tests I wrote to check that both cases are handled correctly.
var test = require("./test");
var requestHandler = require("../server").requestHandler;
var http = require("http");
test(
"should send index.html when / requested", function() {
http.ServerResponse.prototype.end = function(data) {
test.isEqual(data.toString().substr(0, 9), "<!doctype");
};
requestHandler({ url: "/" }, new http.ServerResponse({}));
},
"should send client.js when /client.js requested", function() {
http.ServerResponse.prototype.end = function(data) {
test.isEqual(data.toString().substr(0, 10), ";(function");
};
requestHandler({ url: "/client.js" }, new http.ServerResponse({}));
});
The output when I run these tests:
$ node server_tests.js
..
test.js:12
throw a + " and " + b + " are not equal";
^
<!doctype and ;(function are not equal
An exception is thrown, yet there are two periods indicating two passed tests. Something is wrong.
In the first test, response.end() is mocked with a function that checks that
"<!doctype" is sent to the user. Next, requestHandler() is called, requesting the URL "/". requestHandler() starts reading index.html from disk. While the file is being read, the test framework presses on with its work. Uh oh. That is, the framework prints a period and starts the second test, though the response.end() mock has not asserted the value of the response. response.end() is re-mocked with a function that checks that ";(function" is sent to the user. Double uh oh. requestHandler() is called by the second test. It requests the URL "/client.js". requestHandler() starts reading client.js from disk. The framework prints another premature period.
At some point later, index.html is read from disk. This means that the callback in requestHandler() is called and it calls response.end() with the contents of index.html. Unfortunately, by this time, response.end() has been mocked with a function expecting ";(function". The assertion fails.
This problem can be solved by running tests serially. A test is run. It signals it has finished. The next test is run.
This may seem pedantic. Shouldn’t tests that are testing asynchronous behaviour be able to cope with with the dangers of asynchrony? Well, yes and no. They should certainly test the asynchronous behaviours of requestHandler(). But they should not have to cope with other tests messing about with their execution environment part way through their execution.
(It would be possible to go further and make the tests completely functionally pure. This could be done in a fundamentalist way: the test framework resets the execution context before each test. Or it could be done in a pragmatic way: each test undoes the changes it made to the execution environment. Both ways are outside the scope of this essay.)
I rewrote the testing framework to run asynchronous tests serially. Each asynchronous test binds a done() callback parameter. It calls this when it has made all its assertions. The testing framework uses the execution of this callback as a signal to run the next test. Here are the rewritten tests.
var test = require("./test");
var requestHandler = require("../server").requestHandler;
var http = require("http");
test(
"should send index.html when / requested", function(done) {
http.ServerResponse.prototype.end = function(data) {
test.isEqual(data.toString().substr(0, 9), "<!doctype");
done();
};
requestHandler({ url: "/" }, new http.ServerResponse({}));
},
"should send client.js when /client.js requested", function(done) {
http.ServerResponse.prototype.end = function(data) {
test.isEqual(data.toString().substr(0, 10), ";(function");
done();
};
requestHandler({ url: "/client.js" }, new http.ServerResponse({}));
});
A miniscule asynchronous testing framework
Below is the code for the asynchronous testing framework.
Look at runTests(). It takes userTests, an array that contains the test functions to be run. If that array is empty, the tests are complete and the program exits. If it is not empty, it looks at the length attribute of the next test function. If the attribute has the value 1, the test expects one argument: a done() callback. It runs testAsync(), passing the test function and a callback that prints a period and recurses on runTests() with the remaining test functions.
testAsync() creates a timeout that will fire in one second. It runs the test function, passing a done() callback for the test to run when it is complete. If the callback gets run, the timeout is cleared and testDone() is called to indicate that the next test can run. If the done() callback is never run by the test function, something went wrong. The timeout will fire and throw an exception, and the program will exit.
If the length attribute of the test function has the value 0, the function is run with testSync(). This is the same as testAsync(), except there is no timeout and the testDone() callback is called as soon as the test function has completed.
var test = function() {
runTests(gatherTests(arguments));
};
var runTests = function(userTests) {
if (userTests.length === 0) {
console.log();
process.exit();
} else {
var testDone = function() {
process.stdout.write(".");
runTests(userTests.slice(1));
};
if (userTests[0].length === 1) {
testAsync(userTests[0], testDone);
} else {
testSync(userTests[0], testDone);
}
}
};
var testSync = function(userTest, testDone) {
userTest();
testDone();
};
var testAsync = function(userTest, testDone) {
var timeout = setTimeout(function() {
throw "Failed: done() never called in async test.";
}, 1000);
userTest(function() {
clearTimeout(timeout);
testDone();
});
};
test.isEqual = function(a, b) {
if (a !== b) {
throw a + " and " + b + " are not equal";
}
};
var gatherTests = function(testArgs) {
return Array.prototype.slice.call(testArgs).filter(function(x, i) {
return i % 2 === 1;
});
};
module.exports = test;
Here is the code for the asynchronous testing framework and the new server tests.
An exercise
Now that it is possible to write asynchronous tests, I can write the tests for the server. Or, rather: you can.
If you are not sure where to start, try refactoring the server so the code is more modular. Write a function that sends the passed string with the passed Content-Type to the client. Write a function that reads a static file from disk and responds with the contents. Write a function that converts the current date into "day" or "night". Write a function that takes a request for a certain URL and sends the right response.
Once your refactor is complete, or maybe while it is in progress, you can write your tests.
Summary
I wrote a simple web app. I wrote tests for it and discovered that I could mock the pieces I didn’t want to run when I ran the tests. I discovered that scary things like Ajax and the canvas API really aren’t so scary when I wrote skeletal versions of them. I realised that the mocks I had written were quite verbose. I refactored the web app code to make it more modular. This made the code better and easier to change in the future. It meant I could mock the interfaces I had written, rather than those invented by other people. This meant the mocks became simpler or unnecessary. This made it easier to write tests, so I could write more of them and test the web app more extensively.
I wrote two tests for the server. I discovered that the test framework ran them in parallel, which meant they interfered with each other. I rewrote the test framework to run tests serially. I modified the tests to signal when they were finished. I handed over the rest of the job to you.